# COMPSYS 723 - Final Assessment - First Semester 2020
- 1. Embedded systems and concurrency.
- 1) Explain the need for decomposing software systems into concurrent behaviours and consequently the synchronisation and communication of concurrent behaviours.
- 2) What are the similarities and differences between co-routines and processes?
- 3) Give small examples/scenaria of where the synchronisation and communication of software behaviours happens.
- 4) Define and explain binary and counting semaphores and their typical uses.
- 5) Introduce the notions of unilateral and bilateral rendezvous for synchronisation between pairs of concurrent behaviours and explain when you would use each of them. For examples of implementation of rendezvous use binary semaphores and pseudo-code.
- 6) Explain whether and when synchronisation is necessary for enabling communication of concurrent behaviours and give examples.
- 7) What are the potential problems when using semaphores and state how to avoid them.
- 8) Illustrate in more details two of the problems when using semaphores, the deadlock and priority inversion, in systems with tasks priorities using a timing diagram and explain what are the reasons that cause the problems, as well as how to avoid them by using static and/or dynamic techniques.
- 9) Define non-preemptive and preemptive systems and reflect on their ability to deal with deadlocks and priority inversion, as well as their responsiveness to the external random events.
- 10) How software-implemented behaviours can communicate with hardware-implemented behaviours in hardware/software partitioned systems.
- 2. Real-time operating systems approach to embedded systems design
- 1) What is the role of tasks and what of ISRs in the implementation of those systems?
- 2) What are the “activators” of tasks and ISRs? How are the tasks and ISRs managed by an RTOS? Explain.
- 3) How tasks and ISRs communicate and synchronise in an RTOS (between tasks only and between ISR and task)? Which mechanisms should or should not be used for their synchronisation and communication between a task and an ISR and why?
- 4) What is the underlying “formal” run-time model of a task and what is the equivalent model of an ISR? Illustrate and explain.
- 5) How is memory managed by an RTOS? Why is the allocation/deallocation mechanism different than in general purpose operating systems?
- 6) Which RTOSs are more suitable for real-time systems, non-preemptive or preemptive, and why?
- 7) What are scenaria in which interrupts can cause unwanted effects on systems behaviour and consequently reduced responsiveness in preemptive systems with tasks with priorities?
- 8) What is priority inversion and how can we mitigate it? Illustrate this on the example where you use three tasks with different priorities and an ISR using a timing diagram. Assume that task can control its priority dynamically.
- 9) Draw a simplified diagram depicting your implementation of frequency relay (Assignment 1) and mutual dependencies of concurrent behaviours and activation signals (external and internal) and in one or two sentences explain each.
- 10) Draw the hardware platform diagram and match its features with the diagram depicting software in question 9.
- 3. Concurrent programming language approach to embedded systems design
- 1) List the main features of SystemJ programming/design approach that support complex software systems design.
- 2) Describe Globally Asynchronous Locally Synchronous (GALS) concurrency model of SystemJ and the use of synchronous and asynchronous processes in it. Introduce notions of reactions and clock-domains and their execution models.
- 3) Use a simple graphical representation to illustrate SystemJ program with two clock domains that having two to three synchronous reactions each and explain execution model on this example. Draw a timing diagram that illustrates tick-wise execution of clock domains on two different time-scales.
- 4) Describe in a short paragraph two basic objects for communication and synchronisation off concurrent behaviours, signals and channels, and their semantics.
- 5) Why emission of signals by different reactions within a clock domain never results in causal dependencies and deadlock in execution of reactions?
- 6) What is the role of Java as a “host” language for standard SystemJ? How SystemJ statements and Java statements communicate within reactions?
- 7) Under what conditions channel communication would cause blocking of the execution of a clock domain and how would you mitigate it?
- 8) Illustrate how SystemJ can be used for simultaneous development of a software system and its testbed?
- 9) What are the main mechanisms used to provide reactivity of SystemJ programs, clock domains and reactions and how they work.
- 10) Why SystemJ programs naturally land on distributed computing platforms? What is natural minimal design entity to execute on the same processor (JVM)?
- 4. Synchronous programming in Esterel.
- (a) Identify causal loops, if any, in Code 1 and fix them. Write the correct Esterel program and draw the hardware circuit generated from the correct Esterel program.
- (b) Express the Esterel code segment in Code 2 as a single (flat) Mealy machine. Signals O1 and O2 are outputs to the environment, while S is an internal signal.
- 5. Statechart, Mealy machine, and concurrency.
- 6. Safe State Machine, Statechart, and Mealy machine.
- (a) Give an equivalent single (flat) Mealy machine representation for the three concurrent processes represented as a Safe State Machine (SSM) in Figure 4. A, B, and C are input signals from the environment and O is an output signal.
- (b) List at least two differences and two similarities between Statechart and Safe State Machine (SSM).
# 1. Embedded systems and concurrency.
Questions:
Embedded and real-time systems are most often implemented on resource-constrained platforms and typically consist of a set of functions implemented as software behaviours that are activated by external events, triggered by timers and by other software behaviours.
These behaviours are concurrent as they need to coexist with each other at the same time, synchronize and communicate.
Answer any eight (8) out of 10 following questions. Only the first eight answered questions will be marked. In answers write the question number as shown below.
# 1) Explain the need for decomposing software systems into concurrent behaviours and consequently the synchronisation and communication of concurrent behaviours.
Answer
The process of breaking down a complex software system into concurrent behaviors is critical for multiple reasons:
Efficient Resource Utilization: Modern systems have multiple cores and processors that can execute different tasks simultaneously. Decomposing software systems into concurrent behaviors allows us to exploit these hardware capabilities and maximize the use of resources, leading to improved system performance and efficiency.
Scalability: As systems scale, the amount of data to process and the number of tasks to perform can significantly increase. By designing software to handle concurrent behaviors, it becomes more feasible to scale the system horizontally by simply adding more processing units.
Responsiveness: In interactive systems like web servers or user interfaces, concurrency can help ensure responsiveness. While one task is waiting for a certain resource (like a network response), other tasks can continue, maintaining the system's responsiveness.
Modularity: Decomposing a software system into concurrent behaviors can help with the software's structure and organization. Each concurrent task can be designed, implemented, and tested separately, making the software easier to understand, maintain, and evolve.
However, decomposing software systems into concurrent behaviors introduces the need for synchronization and communication among these behaviors.
Synchronization is essential because concurrent behaviors often need to coordinate their actions. For example, if two tasks are both trying to update the same piece of data, they need to synchronize to ensure that they don't interfere with each other and cause data inconsistency or other issues, a problem known as a race condition.
Communication is also crucial. Concurrent behaviors often need to exchange information to complete their tasks. This exchange can be complicated if the tasks are running on different cores, processors, or machines. This challenge has led to various mechanisms for inter-task communication, such as shared memory, message passing, and event-driven programming.
Managing synchronization and communication can be complex and error-prone, but they are essential for developing effective, efficient, and reliable concurrent software systems. Various tools and strategies, such as locks, semaphores, monitors, or message queues, are used to handle these concerns. Furthermore, several design patterns and architectural styles, such as the actor model or event-driven architecture, can also help structure concurrent systems to simplify synchronization and communication.
# 2) What are the similarities and differences between co-routines and processes?
Answer
Co-routines and processes are two different mechanisms used in computer science for multitasking and concurrent programming. Here's how they compare:
Similarities
Concurrent Execution: Both co-routines and processes can be used to achieve concurrent execution in a program. This means that the program can be doing multiple things "at the same time," even though the actual implementation of this concurrent execution can be different.
Control Transfer: Both mechanisms provide ways to transfer control between different parts of a program. For processes, this is done through context switching, where the operating system suspends one process and resumes another. For co-routines, control transfer is achieved through yield and resume operations.
Differences
Scheduling: One of the main differences is how they are scheduled. Processes are scheduled by the operating system (preemptive scheduling), meaning they can be interrupted at any time to allow another process to run. On the other hand, co-routines are cooperatively scheduled, which means they decide when to yield execution to another co-routine. This makes co-routines lighter weight, but it also means that a misbehaving co-routine could hog the processor.
Memory: Each process has its own memory space, which is isolated from the memory spaces of other processes. This makes processes more secure and less prone to bugs, but it also makes inter-process communication more complex and expensive. Co-routines, on the other hand, share the same memory space (as they exist within the same process), which makes communication between them easier, but they have to be more careful to avoid data races and other synchronization issues.
Switching Overhead: Context switching between processes is a heavy operation because it involves saving and restoring the process state, including memory maps, registers, and other information. Switching between co-routines is typically much faster, as it mostly involves just swapping the execution stack, which makes them more suitable for tasks requiring frequent switches.
Concurrency vs Parallelism: Co-routines provide concurrency but not true parallelism; they can run on only one CPU core at a time. In contrast, processes can be executed in parallel on different CPU cores, assuming the hardware supports it. This allows processes to take full advantage of multi-core systems.
In summary, both co-routines and processes have their uses, and the best one to use depends on the specific requirements of the task at hand.
# 3) Give small examples/scenaria of where the synchronisation and communication of software behaviours happens.
Answer
Certainly, let's consider a couple of real-world examples where synchronization and communication of software behaviors are crucial.
Example 1: Banking System
Imagine a banking system where multiple ATMs (Automated Teller Machines) and online banking portals are making requests to withdraw funds from the same account. Here, synchronization is necessary to prevent a race condition, which could allow the account to be overdrawn.
Let's assume the account has $1000, and two separate withdrawal requests of $700 each are made almost simultaneously from an ATM and an online banking portal. Without synchronization, both systems might check the balance, see that $1000 is available, and proceed with the transactions. This would result in the account being overdrawn by $400, which should not be allowed.
To prevent this, the system might use a lock or other synchronization mechanism. When one transaction checks the account balance, it locks the account for changes. The other transaction has to wait until the first transaction is completed and the lock is released. This ensures that the transactions are effectively serialized, and the account can't be overdrawn.
Example 2: Producer-Consumer Problem
Consider a video streaming service, where one part of the system (the producer) is responsible for encoding video frames, and another part (the consumer) is responsible for sending these frames to the user. Here, the communication between the producer and the consumer is vital, and they also need to synchronize to ensure that frames are not dropped or duplicated.
One common solution is to use a buffer to communicate between the producer and the consumer. The producer adds encoded frames to the buffer, and the consumer removes frames from the buffer to send them. They must synchronize access to this shared buffer to avoid problems. For example, the consumer must wait if the buffer is empty (there's nothing to consume), and the producer must wait if the buffer is full (there's no room to produce).
These are just a couple of examples, but synchronization and communication between software behaviors are necessary in almost any system that involves concurrent or parallel processing.
Race condition
A race condition is a situation in concurrent programming where two or more threads can access shared data and they try to change it at the same time. This could lead to unpredictable and undesirable outcomes, especially when the order of operations or the precise timing of those operations affects the result.
Here's a simple example:
Let's say you have two threads that are both trying to increment the value of a shared integer. The operation of incrementing an integer is typically done in three steps: reading the current value, adding one to it, and writing the new value back.
If these steps are not done atomically (i.e., as one indivisible operation), a race condition could occur. Suppose thread A reads the value, then thread B reads the same value before A can write back. Both A and B will then increment the same value and write back, resulting in the integer being incremented only once, even though two increment operations were performed.
Race conditions can lead to data inconsistencies and hard-to-debug issues in your software. As such, various synchronization mechanisms are used to prevent them, such as locks, semaphores, and atomic operations. These ensure that only one thread can execute a critical section of code that modifies shared data at a time, preventing the simultaneous modifications that can lead to race conditions.
# 4) Define and explain binary and counting semaphores and their typical uses.
Answer
Semaphores are synchronization primitives used in concurrent programming to control access to a common resource by multiple processes or threads and prevent race conditions. A semaphore maintains a set of permits; a thread can either acquire a permit or release a permit.
There are two types of semaphores, binary and counting:
1. Binary Semaphore:
A binary semaphore, also known as a mutex (short for "mutual exclusion"), has only two values: 0 and 1. It's used to ensure that only one thread executes some specific piece of code at any given time. It is termed "binary" because it can only have two states - locked (0) or unlocked (1).
When a thread wants to enter a critical section of code, it checks the binary semaphore. If the semaphore is 1 (unlocked), the thread enters the critical section and changes the semaphore to 0 (locked). Any other thread that wants to enter the critical section while the semaphore is 0 will have to wait. When the thread in the critical section finishes, it sets the semaphore back to 1, allowing other threads to enter.
2. Counting Semaphore:
A counting semaphore is a generalization of a binary semaphore. It can hold any non-negative integer value (not just 0 or 1). This type of semaphore is used when you have multiple instances of a resource available, not just one.
When a thread wants to access one of the resources, it checks the semaphore. If the semaphore's value is greater than 0, the thread decrements the semaphore and proceeds to use the resource. If the semaphore's value is 0, the thread has to wait. When a thread finishes using a resource, it increments the semaphore, signaling that a resource has been freed.
For example, consider a scenario where you have a pool of database connections. A counting semaphore could be used to control access to the connections. When the semaphore's value is 0, all connections are in use, and any thread that wants a connection must wait.
In summary, semaphores provide a way to ensure controlled access to shared resources, which is crucial in multi-threaded or multi-process environments to prevent race conditions and ensure data integrity.
# 5) Introduce the notions of unilateral and bilateral rendezvous for synchronisation between pairs of concurrent behaviours and explain when you would use each of them. For examples of implementation of rendezvous use binary semaphores and pseudo-code.
Answer
Rendezvous is a form of synchronization in concurrent computing where two or more tasks or threads need to wait for each other to reach a certain point of execution before proceeding.
There are two types of rendezvous: unilateral and bilateral.
1. Unilateral Rendezvous:
In unilateral rendezvous, one thread, say A, waits for another thread, say B, to reach a certain point. Once B reaches the specified point, A can continue execution. This is a one-way synchronization; B doesn't wait for A.
This kind of synchronization is often used when one task depends on the results produced by another task. For example, if thread A is computing some data that thread B needs, thread B will have a unilateral rendezvous at the point where it uses the data, waiting until thread A has computed it.
Here's a pseudo-code example using a binary semaphore ("sem" initially set to 0):
# Thread A
compute_data()
sem.signal() # Signal that the data is ready
# Thread B
sem.wait() # Wait for the signal that the data is ready
use_data()
2
3
4
5
6
7
2. Bilateral Rendezvous:
In bilateral rendezvous, both threads wait for each other to reach a certain point before continuing. This form of synchronization ensures that both tasks have completed certain parts of their execution before either proceeds.
This is useful when tasks need to synchronize their activities. For example, in a client-server model, the client might need to wait for the server to be ready before sending a request, and the server might need to wait for the client's request before processing it.
Here's a pseudo-code example using two binary semaphores ("semA" and "semB" initially set to 0):
# Thread A
prepare_data()
semB.signal() # Signal that A is ready
semA.wait() # Wait for B to be ready
send_data()
# Thread B
semB.wait() # Wait for A to be ready
prepare_to_receive()
semA.signal() # Signal that B is ready
receive_data()
2
3
4
5
6
7
8
9
10
11
In this case, each thread signals that it's ready and waits for the other thread to be ready before proceeding.
Remember that while semaphores are a common way to implement rendezvous, other synchronization primitives, like condition variables or barriers, might be more suitable in certain scenarios, depending on the specific requirements and the characteristics of the programming language or system you're using.
# 6) Explain whether and when synchronisation is necessary for enabling communication of concurrent behaviours and give examples.
Answer
Synchronization is typically necessary for communication between concurrent behaviors in the following scenarios:
Shared Memory: When concurrent tasks communicate by accessing shared memory, synchronization is necessary to ensure that data remains consistent and no race conditions occur. For example, in a producer-consumer scenario, the producer and consumer use a shared buffer to communicate. The producer adds items to the buffer, and the consumer removes items. Synchronization is needed to ensure that the producer doesn't add items when the buffer is full, and the consumer doesn't remove items when the buffer is empty.
Inter-Process Communication (IPC): When processes communicate through IPC mechanisms like pipes, message queues, or shared memory, synchronization is necessary to manage access to the IPC resource. For example, if multiple processes are sending messages to the same message queue, synchronization is needed to ensure that the messages don't get mixed up or lost.
Database Access: When multiple threads or processes are accessing and modifying a shared database, synchronization is required to ensure data integrity and prevent conflicts. For example, if two threads try to update the same record in a database at the same time, synchronization can ensure that the updates are applied in the correct order.
File System Access: Similar to database access, when multiple threads or processes are reading from and writing to the same file, synchronization is necessary to prevent data corruption or inconsistency.
In all these cases, synchronization helps to control access to shared resources and coordinate the actions of concurrent tasks, ensuring that they communicate correctly and that their operations on shared data are consistent. However, it's important to manage synchronization carefully, as overuse or incorrect use of synchronization can lead to issues like deadlock, livelock, or contention, and it can negatively impact the performance of the system.
# 7) What are the potential problems when using semaphores and state how to avoid them.
Answer
Semaphores are powerful synchronization primitives, but their use can lead to several potential issues if not managed correctly. Some of these issues include:
Deadlock: Deadlock occurs when two or more threads are unable to proceed because each is waiting for the other to release a resource. For example, if thread A acquires semaphore 1 and waits for semaphore 2, while thread B has already acquired semaphore 2 and is waiting for semaphore 1, neither thread can proceed, resulting in a deadlock.
Avoidance: Deadlocks can be avoided by implementing a strict order of acquiring resources. If all threads always request resources in the same order, circular wait conditions that lead to deadlock cannot occur.
Starvation: Starvation occurs when one or more threads are perpetually denied access to resources because other threads are always served first. For example, if some threads have higher priority and keep acquiring the semaphore before other lower-priority threads, the latter may never get access.
Avoidance: Starvation can be mitigated by employing fairness policies when granting access to resources. This could mean using a semaphore that grants permits in a First-In-First-Out (FIFO) order or ensuring that low-priority threads get access to resources after a certain time.
Priority Inversion: Priority inversion occurs when a higher-priority thread is kept waiting because a lower-priority thread holds a semaphore that the higher-priority thread needs. This situation is made worse if an intermediate-priority thread preempts the execution of the lower-priority thread, further delaying the higher-priority thread.
Avoidance: Priority inversion can be handled by using priority inheritance or priority ceiling protocols. In priority inheritance, when a high-priority thread is blocked by a lower-priority thread, the lower-priority thread temporarily inherits the higher priority. In the priority ceiling protocol, a semaphore is assigned a priority ceiling, which is the highest priority of any thread that may acquire it. When a thread acquires any semaphore, its priority is raised to the highest priority ceiling of any semaphore it holds.
Incorrect Usage: Semaphores require careful programming. It's easy to forget to release a semaphore after acquiring it or to forget to handle exceptions properly, leading to semaphores being held indefinitely or not being acquired when needed.
Avoidance: Following good programming practices can help avoid such issues. For example, always release a semaphore in a finally block or use a try-with-resources statement (in languages that support it) to ensure the semaphore is always released. Additionally, thorough testing and code reviews can help catch mistakes and potential issues.
Remember, using semaphores and other synchronization primitives correctly is crucial to ensuring the correct operation and performance of concurrent and parallel software systems.
# 8) Illustrate in more details two of the problems when using semaphores, the deadlock and priority inversion, in systems with tasks priorities using a timing diagram and explain what are the reasons that cause the problems, as well as how to avoid them by using static and/or dynamic techniques.
Answer
Let's illustrate both Deadlock and Priority Inversion in the context of a system with task priorities:
1. Deadlock:
Let's consider two tasks, Task 1 (High priority) and Task 2 (Low priority). Both tasks need to use two shared resources (Resource A and Resource B) to complete their job.
| Time | Task 1 | Task 2 | Resource A | Resource B |
|---|---|---|---|---|
| t0 | WAIT(A) | RUN | Free | Free |
| t1 | RUN | WAIT(B) | Acquired | Free |
| t2 | WAIT(B) | RUN | Acquired | Acquired |
| t3 | WAIT(B) | WAIT(A) | Acquired | Acquired |
In this scenario, at t0, Task 1 is waiting for Resource A, while Task 2 is running. At t1, Task 1 gets the Resource A and runs, while Task 2 is now waiting for Resource B. At t2, Task 1 needs Resource B (which is held by Task 2), and Task 2 is running. At t3, both tasks are waiting for the resource held by the other, resulting in a deadlock.
Avoidance (Deadlock):
Deadlocks can be avoided by implementing a strict order of acquiring resources. If all tasks always request resources in the same order, circular wait conditions that lead to deadlock cannot occur. In our example, if both tasks try to acquire Resource A before Resource B, deadlock will not occur.
2. Priority Inversion:
Let's consider three tasks: Task H (High priority), Task M (Medium priority), and Task L (Low priority). Task L and Task H need a shared resource, and Task M doesn't.
| Time | Task H | Task M | Task L | Shared Resource |
|---|---|---|---|---|
| t0 | WAIT | WAIT | RUN | Acquired |
| t1 | RUN | WAIT | WAIT | Acquired |
| t2 | WAIT | RUN | WAIT | Acquired |
| t3 | WAIT | RUN | RUN | Acquired |
| t4 | RUN | WAIT | WAIT | Free |
At t0, Task L acquires the shared resource. At t1, Task H needs to run, but since the resource is occupied by Task L, it waits, causing Task L to yield the processor. At t2, Task M (which doesn't need the shared resource) preempts Task L because it has a higher priority than Task L. This continues until t3, when Task M yields the processor and Task L can finally release the resource. At t4, Task H can now acquire the resource and run.
Avoidance (Priority Inversion):
Priority inversion can be avoided through a couple of techniques:
Priority Inheritance: In this strategy, when a high-priority task (like Task H) is blocked by a lower-priority task (Task L), Task L inherits the higher priority until it releases the resource. This prevents the medium-priority task (Task M) from preempting Task L.
Priority Ceiling Protocol: In this strategy, a system-wide policy is set where a task that holds a resource assumes the highest priority of any task that could potentially request that resource. This protocol, like priority inheritance, avoids unbounded priority inversion and can prevent deadlocks.
In summary, while semaphores are valuable tools for synchronization, care must be taken to avoid the pitfalls of deadlock and priority inversion. Proper
# 9) Define non-preemptive and preemptive systems and reflect on their ability to deal with deadlocks and priority inversion, as well as their responsiveness to the external random events.
Answer
Non-Preemptive Systems:
In non-preemptive systems, once a process starts executing, it runs to completion or until it voluntarily yields control. Other processes can't interrupt it during its execution. This is a cooperative model because a process controls the CPU for as long as it needs.
Pros:
- Simplicity: Managing resources is simpler because a running task can't be interrupted and have its resources re-allocated.
- Predictability: Given a set of tasks, the execution pattern is predictable and repeatable, which is beneficial in real-time systems.
Cons:
- Deadlocks: These systems can be susceptible to deadlocks if not managed properly. If a process holds a resource and waits for another one held by another process, it will cause a deadlock because there is no mechanism to preempt and resolve the situation.
- Responsiveness: They can be less responsive to external events, particularly if a long-running task is executing.
Preemptive Systems:
In preemptive systems, a running process can be interrupted and moved to a waiting state to allow another process to run. This is typically managed by a scheduler, which allocates CPU time based on priorities or other scheduling rules.
Pros:
- Responsiveness: They are more responsive to external events. A high-priority task can preempt a lower-priority one, making the system more responsive to time-critical tasks.
- Deadlock handling: Preemption allows the system to handle potential deadlocks by interrupting a task that's causing a deadlock condition.
Cons:
- Complexity: Managing resources is more complex. Mechanisms need to be in place to protect shared resources and ensure data consistency when tasks are preempted.
- Priority Inversion: Priority inversion can be a problem if not managed correctly. However, preemptive systems usually incorporate protocols to handle this problem, like Priority Inheritance or Priority Ceiling.
In conclusion, the choice between preemptive and non-preemptive scheduling depends on the specific requirements of the system. Real-time systems often use preemptive scheduling because of its responsiveness, despite the added complexity. However, some simpler or highly predictable systems might benefit from non-preemptive scheduling. As always, it's crucial to understand and manage the potential issues associated with whichever model is used.
# 10) How software-implemented behaviours can communicate with hardware-implemented behaviours in hardware/software partitioned systems.
Answer
Hardware/software partitioned systems are typically designed to leverage the benefits of both software and hardware components. Software-implemented behaviors can communicate with hardware-implemented behaviors in a number of ways:
1. Memory-Mapped I/O: Hardware devices can be controlled and queried using regions of memory that are mapped to device registers. The software writes to or reads from these specific memory addresses to communicate with the hardware. This is a common technique used in embedded systems.
2. Direct Memory Access (DMA): DMA is a feature of computer systems that allows hardware subsystems to access main system memory (RAM) independently of the central processing unit (CPU). It is often used for high-speed I/O devices to provide faster data transfers and free up CPU resources.
3. Interrupts: Hardware devices often communicate with software using interrupts. When a device needs attention from the CPU (e.g., data is ready to be read, or a device operation has completed), it sends an interrupt signal. The CPU then suspends its current operations, saves its state, and executes an interrupt handler function related to the device.
4. Device Drivers: A device driver is a type of software that controls a particular type of hardware device. It serves as the abstraction layer between the hardware and the operating system or other software, translating high-level commands into the low-level commands needed by the device.
5. Hardware Description Languages (HDLs): HDLs like VHDL or Verilog are often used to describe the behaviors of digital systems, including custom hardware accelerators or peripherals. These HDL descriptions can be used to generate RTL (Register Transfer Level) designs that can be integrated with software.
6. Bus interfaces: In many systems, hardware components are connected to a system bus, and software communicates with these components by writing or reading data on the bus. Common bus interfaces include I2C, SPI, and UART, among others.
In a hardware/software co-design approach, decisions about which components to implement in hardware and which to implement in software can have significant impacts on the system's performance, power consumption, and cost. Therefore, it's important to choose the right communication mechanism that suits the system requirements.
# 2. Real-time operating systems approach to embedded systems design
Questions:
Real-time operating system (RTOS) allows specification of two types of software behaviours, tasks and interrupt service routines (ISR), for the design of embedded and real-time software systems.
TIP
Real-Time Operating Systems (RTOS) provide mechanisms for the design of embedded and real-time software systems. In an RTOS, software behaviours are usually classified into two main types: tasks and Interrupt Service Routines (ISRs).
Tasks:
Tasks, also known as threads, are the fundamental units of work scheduled by an RTOS. Each task is a sequence of instructions that performs a specific job. In an RTOS, tasks are typically independent and may run concurrently, depending on the number of cores and threads the processor supports.
Tasks in an RTOS can be assigned different priority levels. The RTOS scheduler determines the execution of tasks based on their priority levels and the scheduling policy (such as Rate-Monotonic or Earliest-Deadline-First). Higher-priority tasks can preempt lower-priority tasks.
Tasks in an RTOS are also designed to be pre-emptible, which means a higher-priority task can "interrupt" a lower-priority task before it has finished executing. This is essential in real-time systems where time-critical tasks must be able to run as soon as they are needed.
Interrupt Service Routines (ISRs):
Interrupt Service Routines (ISRs) are special types of tasks that are triggered by hardware interrupts. When a hardware device triggers an interrupt, the processor suspends the current task, saves its state, and runs the ISR associated with the interrupt.
ISRs are typically short and designed to return control to the interrupted task as quickly as possible. They are used to handle time-critical hardware events that need immediate attention. Longer-duration work triggered by an interrupt is often offloaded to a regular task, which can be scheduled cooperatively with other system tasks.
To prevent conflicts, ISRs usually run with interrupts disabled, which effectively gives them the highest priority in the system. However, because interrupts are disabled, ISRs need to be kept short to avoid impacting the responsiveness of the system to other interrupts.
In summary, tasks and ISRs are two fundamental elements of RTOS-based software design. By carefully partitioning software behaviours into tasks and ISRs, designers can create systems that respond effectively to real-time demands and external events.
Answer any eight (8) out of ten (10) following questions. Only first eight answered questions will be marked. In answers write the question number as shown below.
# 1) What is the role of tasks and what of ISRs in the implementation of those systems?
Answer
Tasks and Interrupt Service Routines (ISRs) are fundamental elements in the implementation of real-time and embedded systems using a Real-Time Operating System (RTOS). They play different roles that complement each other to meet the system's performance and timing requirements.
Tasks:
Tasks form the primary body of the application software. They encapsulate major functionalities of the system and are the basic units of execution that the RTOS schedules. Tasks are typically designed to handle complex, non-time-critical processing, or background tasks.
Tasks can be periodic (i.e., executing at regular intervals, such as control loop tasks), aperiodic (i.e., reacting to sporadic external events), or idle tasks (i.e., executing when the system has no other work to do).
Tasks can be preempted by higher priority tasks, ensuring that the most important tasks in the system are given CPU time first. This preemption capability is critical for achieving the real-time response characteristics required in many embedded systems.
Interrupt Service Routines (ISRs):
ISRs respond to hardware interrupts. They provide a mechanism to react swiftly to immediate hardware events. For example, when data arrives at a network interface, an ISR related to the interface is triggered to process the data.
ISRs are typically designed to be very short in duration to minimize interrupt latency (i.e., the delay before the system begins processing an interrupt). If an ISR has a long processing requirement, it's common to divide the workload between the ISR and a task. The ISR handles the immediate response, then signals a task to perform the remaining processing.
ISRs effectively have the highest priority in the system because they interrupt other tasks, including those running at the highest priority. Because of this, careful design is needed to ensure that ISRs do not monopolize processor time and prevent lower-priority tasks from executing.
In summary, tasks and ISRs have different roles: tasks perform the main work of the application and can be scheduled to manage complex processing requirements, while ISRs respond quickly to immediate hardware events. The combination of these two elements allows for the implementation of systems that can both respond quickly to real-time events and perform complex processing tasks.
# 2) What are the “activators” of tasks and ISRs? How are the tasks and ISRs managed by an RTOS? Explain.
Answer
In a Real-Time Operating System (RTOS), tasks and Interrupt Service Routines (ISRs) are activated in different ways and are managed by the RTOS through its scheduling and interrupt handling capabilities.
Activators:
Tasks: Tasks are typically activated based on the scheduling algorithm used by the RTOS. A task can be activated by timers (for periodic tasks), external events (for event-driven tasks), or by other tasks (via inter-process communication mechanisms like signals or semaphores). Some tasks are also activated when the system boots and run indefinitely.
ISRs: ISRs are activated by hardware interrupts. When a peripheral device generates an interrupt (for instance, when data arrives on a network port, or a timer overflows), the corresponding ISR is invoked by the RTOS's interrupt handling mechanism.
Management by an RTOS:
Tasks: RTOSes manage tasks through a scheduler, which is responsible for determining which task runs at any given time. The scheduler makes these decisions based on a variety of factors, including task priority and the scheduling algorithm used (such as round-robin, priority-based, or deadline-based scheduling). RTOSes also provide mechanisms for tasks to communicate and synchronize with each other, such as queues, semaphores, or signals.
ISRs: ISRs are managed by the RTOS's interrupt handling mechanism. When an interrupt occurs, the RTOS saves the context of the currently running task (or ISR), runs the ISR associated with the interrupt, and then restores the saved context once the ISR completes. To minimize interrupt latency, ISRs are typically designed to perform minimal processing and then signal a task to perform any additional necessary work.
In summary, tasks and ISRs are both crucial parts of an RTOS-based system, but they are activated and managed in different ways. Tasks are activated based on scheduling decisions and external events and are managed by the RTOS scheduler. In contrast, ISRs are activated by hardware interrupts and are managed by the RTOS's interrupt handling mechanism. Understanding these mechanisms is crucial for designing effective real-time and embedded systems.
# 3) How tasks and ISRs communicate and synchronise in an RTOS (between tasks only and between ISR and task)? Which mechanisms should or should not be used for their synchronisation and communication between a task and an ISR and why?
Answer
In a Real-Time Operating System (RTOS), tasks and Interrupt Service Routines (ISRs) need to communicate and synchronize for efficient operation. This is typically achieved through various mechanisms provided by the RTOS.
Communication and Synchronization between Tasks:
Tasks often need to coordinate their work and share data. This can be accomplished using several mechanisms, such as:
Semaphores: These are used to control access to shared resources and prevent race conditions. A binary semaphore (also known as a mutex) ensures that only one task accesses a shared resource at a time.
Message Queues: These provide a mechanism for tasks to pass data to each other. A task can post a message to a queue, and another task can retrieve the message when it's ready to process it.
Signals and Events: These allow one task to notify another task that a particular condition or event has occurred.
Shared Memory: Here, multiple tasks can access the same memory area. However, care must be taken to ensure that access is synchronized correctly to prevent race conditions.
Communication and Synchronization between ISRs and Tasks:
It's common for an ISR to perform some initial processing and then signal a task to perform additional processing. However, because ISRs should be kept as short as possible, and because they run in a different context, the mechanisms for communication and synchronization between ISRs and tasks are often more restricted.
Semaphores: ISRs can use semaphores to signal tasks, but they generally should not wait on a semaphore. Waiting within an ISR would increase the ISR's execution time and could lead to system instability.
Message Queues: Similar to semaphores, ISRs can post messages to a queue, but they should not retrieve messages. This allows an ISR to pass data to a task for further processing.
Signals and Events: These are often used to signal a task from an ISR. The ISR triggers a signal or event, and the task is designed to wait for this signal or event.
The key point is that ISRs should not perform operations that could block, such as waiting on a semaphore or reading from a message queue. These operations increase the ISR's execution time, which should be minimized to ensure the system remains responsive to other interrupts.
Moreover, it's essential to protect shared data that's accessed by both tasks and ISRs to avoid race conditions. This usually involves disabling interrupts temporarily while the shared data is being accessed. However, this should be done judiciously, as excessive disabling of interrupts can lead to missed interrupts or increased interrupt latency.
# 4) What is the underlying “formal” run-time model of a task and what is the equivalent model of an ISR? Illustrate and explain.
Answer
The underlying run-time models of a task and an Interrupt Service Routine (ISR) in a Real-Time Operating System (RTOS) are conceptually distinct due to their different roles and behaviors in the system.
Task Model:
A task, also referred to as a thread, is typically modeled as a sequential execution flow. It can be in one of several states:
- Ready: The task is ready to run and is waiting for the CPU to be assigned to it.
- Running: The task currently has control of the CPU and is executing.
- Blocked: The task is waiting for some event to occur, such as an input/output operation to complete or a semaphore to be signaled.
- Suspended: The task is not ready to run and will not be scheduled until it's explicitly resumed.
A task may transition between these states in response to system events, scheduling decisions, or explicit requests. For example, when a task is running and an interrupt occurs, it moves to the ready state, and the corresponding ISR is invoked.
ISR Model:
An ISR, on the other hand, is modeled as a response to an external interrupt. An ISR doesn't have states like a task does; instead, it's invoked in response to a hardware event and executes to completion without being preempted. Once the ISR finishes execution, control returns to the task that was interrupted, or the scheduler chooses another task to run.
Here's a simplified representation:
Hardware Interrupt -> ISR runs to completion -> Interrupted Task resumes (or another task is scheduled)
ISRs are expected to execute quickly, so they shouldn't perform operations that could block, such as waiting for a semaphore. If an ISR has more complex processing to do, it should signal a task to perform this work.
In summary, the run-time model for a task involves different states and transitions between them in response to various events and conditions. In contrast, an ISR is triggered by a hardware interrupt and runs to completion without being preempted. Understanding these models is crucial for developing and debugging RTOS-based systems.
# 5) How is memory managed by an RTOS? Why is the allocation/deallocation mechanism different than in general purpose operating systems?
Answer
Memory management in a Real-Time Operating System (RTOS) is typically more deterministic and simplified compared to a General-Purpose Operating System (GPOS). This is due to the real-time requirements and resource-constrained environments of embedded systems.
In a GPOS, like Linux or Windows, memory allocation and deallocation are generally handled by complex algorithms to optimize the usage of large amounts of memory, handle fragmentation, and support a variety of applications and user needs. The trade-off is that memory operations in a GPOS can be non-deterministic – you cannot precisely predict when the allocation will be completed, which is not suitable for real-time systems where predictability is crucial.
On the other hand, an RTOS tends to adopt simpler and more deterministic memory management strategies to meet the real-time requirements:
Static Memory Allocation:
RTOSes often use static memory allocation, where all memory needs are determined before the program runs. This method is deterministic and avoids issues like fragmentation but can be inflexible as the memory requirements must be known in advance and cannot be changed during runtime.
Pool Allocation:
RTOSes can also use a pool allocation system where memory is divided into fixed-sized blocks. When a task needs memory, it is given one or more of these blocks. This method reduces fragmentation and is more predictable than dynamic allocation, but it can lead to inefficient memory use if the block sizes don't closely match the tasks' needs.
Stack Allocation:
Each task in an RTOS typically has its own stack, which is allocated when the task is created and deallocated when the task ends. This is used for automatic variables and for saving context during task switches. The size of each stack must be carefully chosen to be large enough for the task's needs but not so large as to waste memory.
Heap Allocation:
Although less common due to the risks of fragmentation and non-determinism, some RTOSes do provide a heap for dynamic memory allocation. However, this is typically used sparingly and with caution.
In conclusion, the memory management mechanism in an RTOS differs from a GPOS due to the different requirements of the systems where they are used. An RTOS is designed to be predictable and efficient in constrained environments, leading to different trade-offs in memory management compared to a GPOS.
# 6) Which RTOSs are more suitable for real-time systems, non-preemptive or preemptive, and why?
Answer
The choice between non-preemptive and preemptive Real-Time Operating Systems (RTOSs) largely depends on the specific requirements of the system being developed. Both types of RTOSs have their own advantages and appropriate use cases.
Preemptive RTOSs are generally more suitable for complex real-time systems where tasks have differing criticality levels, and strict timing requirements must be met. Preemption allows a high-priority task to interrupt a lower-priority task, ensuring that critical tasks can run as soon as they are ready. This makes preemptive RTOSs highly responsive to real-time events, but they are also more complex due to the need for synchronization mechanisms to handle shared resources.
Non-preemptive RTOSs, where a task, once started, runs to completion and can't be interrupted by another task, have advantages in systems with less stringent timing requirements or where tasks are simple, short, and largely independent. They can be simpler to design and debug because you don't have to worry about issues like race conditions between tasks. However, non-preemptive systems can be less responsive to real-time events because a new high-priority task must wait until the currently running task completes.
In general, preemptive RTOSs are more commonly used in real-time systems due to their improved responsiveness to real-time events and their ability to handle complex tasks with varying levels of criticality. Non-preemptive RTOSs are simpler but can be less flexible and responsive, making them more suitable for less complex systems or systems with less stringent timing requirements.
Remember that the choice between preemptive and non-preemptive scheduling is just one of many factors to consider when choosing or designing an RTOS for a real-time system. Other factors include the system's hardware, the complexity of the tasks it will be running, its timing and reliability requirements, and the skills and experience of the development team.
# 7) What are scenaria in which interrupts can cause unwanted effects on systems behaviour and consequently reduced responsiveness in preemptive systems with tasks with priorities?
Answer
Interrupts can certainly have unintended impacts on system behavior and responsiveness in preemptive systems with priority-based tasks. Here are some common scenarios:
Interrupt Starvation: If interrupts occur too frequently or the Interrupt Service Routines (ISRs) take too long to execute, the system might spend most of its time servicing interrupts. This can delay task scheduling and execution, leading to task starvation, especially for lower priority tasks.
Priority Inversion: This can happen when a low-priority task acquires a shared resource (via a mutex or semaphore), and then a high-priority task preempts it. If the high-priority task needs the same resource, it will be blocked until the low-priority task releases it, which could be delayed further if medium-priority tasks preempt the low-priority task. This situation contradicts the priority system and could lead to missed deadlines.
Interrupt Latency: In a system with many high-priority tasks, a newly arriving interrupt may have to wait for a currently executing high-priority task to complete before its ISR can run, leading to increased interrupt latency.
Race Conditions: If an ISR and a task access the same shared resource, and the ISR can interrupt the task, there's a potential for race conditions, where the task might see inconsistent state if interrupted in the middle of an update.
To manage these issues, designers need to use proper strategies such as:
- For priority inversion, protocols like Priority Inheritance or Priority Ceiling can be used.
- Interrupts can be masked during critical sections of code to prevent race conditions.
- Keeping ISRs short and having them signal tasks to do more substantial work can reduce the time spent in interrupt context, decreasing the chances of interrupt or task starvation.
- Consideration of all these factors during system design and testing can help maintain system responsiveness and meet real-time requirements.
# 8) What is priority inversion and how can we mitigate it? Illustrate this on the example where you use three tasks with different priorities and an ISR using a timing diagram. Assume that task can control its priority dynamically.
Answer
Priority Inversion is a scenario in a scheduling system where a higher priority task is indirectly preempted by a lower priority task effectively "inverting" their priorities. This is a critical problem in real-time operating systems, as it could lead to higher priority tasks missing their deadlines.
Consider a system with three tasks: Task A with high priority, Task B with medium priority, and Task C with low priority. Also, consider an Interrupt Service Routine (ISR).
Here's an example scenario:
- Task C, the low priority task, gains access to a shared resource (using a mutex or semaphore).
- Task A, the high priority task, becomes ready to run and preempts Task C because Task A has a higher priority. Task A then tries to access the same shared resource that Task C is holding, but since Task C hasn't released it yet, Task A is blocked.
- While Task A is blocked and Task C is ready to run, Task B (medium priority) becomes ready. Since Task B has higher priority than Task C but lower than Task A, Task B preempts Task C.
- Task C can't run until Task B is finished. This means Task A, the highest priority task, remains blocked because it's waiting for the shared resource that Task C holds, and Task C can't release it because Task B is running. This situation is a classic example of priority inversion.
To mitigate priority inversion, we can use protocols like Priority Inheritance or Priority Ceiling.
Priority Inheritance is a protocol where, when a high priority task (Task A) is blocked by a lower priority task (Task C) holding a mutex, the priority of the blocking task (Task C) is temporarily bumped up to the priority of the higher priority task (Task A). This ensures that the lower priority task can finish its work and release the resource, after which it will return to its original priority.
In our example, when Task A is blocked by Task C, Task C inherits the priority of Task A. Now, even if Task B becomes ready, it can't preempt Task C (which now has high priority). Task C can quickly finish its work, release the shared resource, and allow Task A to proceed.
Priority Ceiling is another protocol where each mutex (shared resource) is assigned a "priority ceiling" - the highest priority of any task that may lock the mutex. A task can only lock a mutex if the task's priority is higher than the priority ceilings of all currently locked mutexes. This prevents a lower priority task from locking a mutex that a higher priority task might soon need.
Both these protocols can be employed dynamically at runtime, offering a solution to the priority inversion problem and ensuring that higher priority tasks can meet their deadlines. However, they do add some complexity to the scheduling system and require careful design and analysis to use correctly.
# 9) Draw a simplified diagram depicting your implementation of frequency relay (Assignment 1) and mutual dependencies of concurrent behaviours and activation signals (external and internal) and in one or two sentences explain each.
WARNING
To do
# 10) Draw the hardware platform diagram and match its features with the diagram depicting software in question 9.
WARNING
To do
# 3. Concurrent programming language approach to embedded systems design
Questions:
Concurrency can be described and then implemented in different ways. In this section we demonstrate it by using a concurrent programming language SystemJ. The list of SystemJ kernel statements is given in Table 1.
| Statements | Description |
|---|---|
| p;q | p1 and p2 in sequence (sequential composition) |
| pause | Consumes a logical instant of time (a tick boundary) |
| [input|output] [type] signal ID | Signal declaration |
| emit ID[(expr)] | Emitting a signal with a possible value |
| [while(true)|loop] p | Temporal loop |
| present(ID) p else q | If signal ID is present enter p else q |
| [weak] abort ([immediate] ID) p do q | Preempt if signal ID is present |
| [weak] suspend ([immediate] ID) p | Suspend for one tick if signal ID is present |
| trap(ID) p do q | Software exception; preempt if exit(ID) is executed in p |
| exit(ID) | Throw an exception with a token ID |
| p | |
| [input|output] type channel ID | Channel declaration |
| send ID(exp) | Send data exp over the channel ID |
| receive ID | Receive data on channel ID |
| #ID | Retrieve data from a valued signal ID or channel ID |
SystemJ is a concurrent programming language for designing and implementing reactive and real-time systems. It brings together the disciplines of synchronous reactive and asynchronous programming, providing mechanisms to handle concurrency in a systematic manner. Here's a brief overview of the core SystemJ kernel statements listed:
p;q: Executes statements p and q sequentially. It first executes p and then executes q.
pause: Consumes a logical instant of time (a tick boundary), forcing synchronization points in the program.
[input|output] [type] signal ID: This is for signal declaration. It declares an input or output signal with a specific type and ID.
emit ID[(expr)]: Emits a signal with a possible value. This is used for inter-process communication.
[while(true)|loop] p: Executes statement p in a temporal loop, which means it will repeatedly execute p.
present(ID) p else q: If signal ID is present, it executes p. Otherwise, it executes q.
[weak] abort ([immediate] ID) p do q: If signal ID is present, it preempts p and executes q.
[weak] suspend ([immediate] ID) p: If signal ID is present, it suspends p for one tick.
trap(ID) p do q: Sets up a software exception, preempting p and executing q if exit(ID) is executed in p.
exit(ID): Throws an exception with a token ID. It is used with the trap statement.
p || q: Executes p and q in lock-step parallel (synchronously). This is used for synchronous parallel composition.
[input|output] type channel ID: Declares a channel with a specific type and ID for communication.
send ID(exp): Sends data exp over the channel ID.
receive ID: Receives data on channel ID.
#ID: Retrieves data from a valued signal ID or channel ID.
These statements allow the SystemJ programmer to express complex, concurrent behaviors with precise control over synchronization and communication. They also provide mechanisms for handling exceptional conditions, which can be crucial in reactive and real-time systems.
# Derived Constructors

# SystemJ programming/design
To understand the core concepts of SystemJ programming, focus on these key elements:
Reactive Programming: SystemJ is built on the principles of reactive programming, which means it is designed for systems that respond to external events or signals. Understanding this model is crucial for working with SystemJ.
Clock Domains: These are the fundamental units of synchrony and concurrency in SystemJ. Each clock domain operates independently from the others and can be thought of as a separate synchronous system.
Reactions: Within each clock domain, reactions are blocks of code that are triggered by specific signals or conditions. They are written in Java and are atomic within a clock domain, meaning they can't be interrupted by other reactions within the same clock domain.
Signals: These are the primary means of communication and synchronization in SystemJ. Signals can be emitted by reactions and can carry data. Signals can be tested for presence or absence in a reaction.
Channels: These are used for inter-clock-domain communication. Channels are unidirectional and are used to send data from one clock domain to another.
SystemJ Statements: There are several specific syntax elements in SystemJ, such as
emit,present,pause, etc. that control the flow of execution within a clock domain and enable synchronization between different clock domains.Host Language (Java): SystemJ leverages Java as its host language. This means the actual computation or data manipulation within reactions is done using Java code. Also, Java's capabilities can be used for interacting with external systems.
By focusing on these concepts, you'll understand the most significant portion of SystemJ. You'll be able to write programs that respond to signals, synchronize and communicate between different clock domains, and perform computation within reactions.
Remember, this is the 20% that gets you 80% of the way. For the remaining 20%, you'll need to dive deeper into advanced features and edge cases in SystemJ programming, which can be picked up as you gain more experience working with the language.
Answer any eight (8) out of ten (10) following questions. Only first eight answered questions will be marked. In answers write the question number as shown below.
# 1) List the main features of SystemJ programming/design approach that support complex software systems design.
Answer
SystemJ is a high-level programming language designed to address the needs of complex, concurrent, and real-time system design. Here are some of its main features that support these needs:
Synchronous and Asynchronous Programming: SystemJ supports both synchronous and asynchronous models of computation. This allows for the design of reactive systems (which respond to the environment in a timely manner), as well as systems where different components can proceed independently at their own pace.
Concurrency and Synchronization: SystemJ provides constructs for designing concurrent systems and for controlling the synchronization between different parts of the system. This is crucial in modern software systems where parallel execution is the norm.
Signal-based Communication: SystemJ uses signals for inter-process communication. Signals can be emitted and checked for presence in a safe manner, which provides a reliable mechanism for communication between concurrent parts of a system.
Temporal Scoping and Preemption: SystemJ includes mechanisms for temporal scoping and preemption of execution. This can be used to design complex behaviors where certain actions are only valid in specific contexts or where actions should be interrupted under certain conditions.
Exception Handling: SystemJ provides a mechanism for handling exceptions, allowing the system to respond to error conditions or other unexpected events in a controlled manner.
Modularity and Encapsulation: In SystemJ, a system is composed of independent, encapsulated entities called "clock-domains". Each clock-domain has its own local state and behavior, and can interact with others through signals. This promotes modularity and separation of concerns in system design.
Formal Semantics: SystemJ is based on a formal semantics, which gives a precise meaning to SystemJ programs. This can be used to reason about system behavior, and can also support formal verification methods.
These features make SystemJ a powerful tool for designing complex software systems, particularly those with real-time or reactive requirements. It provides a high level of abstraction, which can help manage the complexity of modern software systems.
# 2) Describe Globally Asynchronous Locally Synchronous (GALS) concurrency model of SystemJ and the use of synchronous and asynchronous processes in it. Introduce notions of reactions and clock-domains and their execution models.
Answer
The Globally Asynchronous Locally Synchronous (GALS) model is a concurrent system design paradigm that combines both asynchronous and synchronous models of computation. This model is implemented in SystemJ, which is designed to handle the challenges of designing complex concurrent systems.
In the GALS model, the system is divided into several locally synchronous subsystems or modules, referred to as clock domains in SystemJ. Each clock domain operates at its own pace, and interactions between them are asynchronous. Within each clock domain, operations are synchronous and are triggered by a local clock, making behavior predictable and deterministic.
A clock domain encapsulates a synchronous reactive system that interacts with its environment and other clock domains in discrete logical steps, known as reactions. A reaction is an atomic computational step where inputs are sampled, computation is performed, and outputs are produced.
This design principle allows SystemJ to provide the benefits of both synchronous (deterministic behavior, ease of reasoning) and asynchronous (modularity, scalability) design approaches. Here's a brief explanation of the notions of reactions and clock-domains:
Reactions: A reaction is a single execution step in a synchronous system. During a reaction, the system reads its inputs, performs some computation, and then updates its outputs. Reactions are atomic and consistent: they are perceived as happening instantaneously from the point of view of the rest of the system. In other words, no other activities in the system can observe the intermediate states during a reaction. This provides a clear and simple semantics for concurrent activities within a clock domain.
Clock-Domains: In SystemJ, a clock domain is an encapsulated concurrent component that operates synchronously. Each clock domain has its own local clock, and all activities within a clock domain are synchronized to this clock. The boundaries between clock domains represent asynchronous interfaces, where communication is done via signals. Each clock domain can progress at its own pace, independently from the others, which allows for a high degree of modularity and flexibility in system design.
This combination of synchronous and asynchronous design principles allows SystemJ to manage the complexity of concurrent system design, and supports the development of highly modular, scalable, and reliable systems.
# 3) Use a simple graphical representation to illustrate SystemJ program with two clock domains that having two to three synchronous reactions each and explain execution model on this example. Draw a timing diagram that illustrates tick-wise execution of clock domains on two different time-scales.
DETAILS
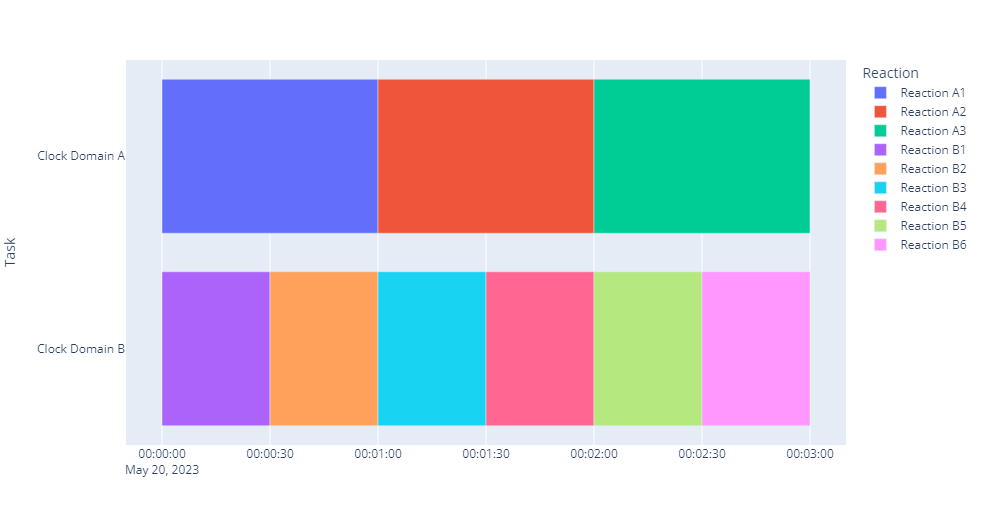
This diagram represents two clock domains A and B, each having different reactions happening at different times. Each row represents a reaction within a clock domain, and the length of each row represents the duration of that reaction. In Clock Domain A, reactions A1, A2, and A3 take place sequentially each for a duration of one minute. In Clock Domain B, reactions B1 through B6 take place sequentially each for a duration of half a minute.
In a SystemJ program, each clock domain operates independently but in a synchronous manner. This means that within a single clock domain, all reactions occur in a lock-step fashion, one reaction completing before the next one begins. For instance, in Clock Domain A, Reaction A1 completes before Reaction A2 begins, and so on. This is depicted in the timing diagram by the sequential non-overlapping time intervals for each reaction.
Across different clock domains, the reactions can occur on different time-scales. For instance, the reactions in Clock Domain B are happening twice as fast as those in Clock Domain A. This is an example of Globally Asynchronous, Locally Synchronous (GALS) model, where each clock domain operates synchronously internally, but asynchronously with respect to each other.
import plotly.express as px
import pandas as pd
# The data for the timing diagram
df = pd.DataFrame([
dict(Task="Clock Domain A", Start='2023-05-20 00:00:00', End='2023-05-20 00:01:00', Reaction="Reaction A1"),
dict(Task="Clock Domain A", Start='2023-05-20 00:01:00', End='2023-05-20 00:02:00', Reaction="Reaction A2"),
dict(Task="Clock Domain A", Start='2023-05-20 00:02:00', End='2023-05-20 00:03:00', Reaction="Reaction A3"),
dict(Task="Clock Domain B", Start='2023-05-20 00:00:00', End='2023-05-20 00:00:30', Reaction="Reaction B1"),
dict(Task="Clock Domain B", Start='2023-05-20 00:00:30', End='2023-05-20 00:01:00', Reaction="Reaction B2"),
dict(Task="Clock Domain B", Start='2023-05-20 00:01:00', End='2023-05-20 00:01:30', Reaction="Reaction B3"),
dict(Task="Clock Domain B", Start='2023-05-20 00:01:30', End='2023-05-20 00:02:00', Reaction="Reaction B4"),
dict(Task="Clock Domain B", Start='2023-05-20 00:02:00', End='2023-05-20 00:02:30', Reaction="Reaction B5"),
dict(Task="Clock Domain B", Start='2023-05-20 00:02:30', End='2023-05-20 00:03:00', Reaction="Reaction B6"),
])
# Create the Gantt chart
fig = px.timeline(df, x_start="Start", x_end="End", y="Task", color="Reaction")
fig.update_yaxes(autorange="reversed") # Reverse the order of tasks on the y-axis
fig.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 4) Describe in a short paragraph two basic objects for communication and synchronisation off concurrent behaviours, signals and channels, and their semantics.
Answer
Signals and channels are fundamental objects for communication and synchronization in concurrent programming systems, each with its own semantics.
1. Signals: A signal represents a form of communication that is usually event-driven. When a specific event occurs, a signal is generated (emitted) to indicate the occurrence of the event. These signals can be listened for (or "waited on") by other parts of the system. In some concurrent programming systems, signals can also carry a value, providing a way to pass data along with the event notification. The semantics of signals are usually non-blocking, meaning that emitting a signal does not block the execution of the emitter, and signals can be emitted multiple times.
2. Channels: A channel provides a conduit for sending data between different concurrent tasks or processes. Channels are used for inter-process communication and often implement different synchronization mechanisms, such as blocking/non-blocking or synchronous/asynchronous communication. A task may send a message into a channel, and another task can receive the message from the channel. The semantics of channels are often blocking: if a task tries to send a message over a channel and there's no room, it will block until there's space. Similarly, if a task tries to receive from an empty channel, it will block until a message arrives.
In essence, both signals and channels facilitate communication and synchronization among concurrent tasks. However, signals are typically used for event-driven communication and may be more suited for coordination and synchronization, while channels provide a way to send and receive data between tasks.
# 5) Why emission of signals by different reactions within a clock domain never results in causal dependencies and deadlock in execution of reactions?
Answer
Emission of signals by different reactions within a clock domain does not result in causal dependencies or deadlock due to the local synchronous execution model and the concept of logical instants in the clock domain.
The local synchronous execution model is characterized by an instant-wise execution of reactions. In each logical instant, every reaction within the clock domain can read signals that were emitted in the previous instant, execute based on those values, and emit new signals.
All of these steps are considered to be happening "atomically" - that is, from the perspective of reactions in the same clock domain, all signal emissions appear to happen simultaneously at the end of the logical instant, regardless of the order in which they actually occurred. This model prevents causal dependencies because every reaction has a consistent view of the signals at each logical instant, and changes to signals only become visible at the next instant.
Additionally, because each reaction within the clock domain is guaranteed to progress to the next logical instant after it finishes its work for the current instant, deadlocks within a clock domain are also prevented. There's no way for reactions to wait for each other within a single instant, because they all progress to the next instant together.
Therefore, the combination of the instant-wise execution model and the atomicity of signal emissions within each instant ensures that emission of signals by different reactions within a clock domain does not result in causal dependencies or deadlock.
# 6) What is the role of Java as a “host” language for standard SystemJ? How SystemJ statements and Java statements communicate within reactions?
Answer
In SystemJ, Java is the "host" language, which means it is the programming language used to write the sequential or procedural parts of a SystemJ program. The concurrent and synchronous parts are written using the SystemJ kernel language, which is a set of control-flow constructs used for specifying concurrency and timing behavior.
Java plays several key roles in a SystemJ program:
Sequential Logic: The logic within reactions (individual actions) is written in Java. This includes arithmetic operations, data manipulations, and other standard programming tasks.
Interaction with External Systems: Java code is used to interact with external systems, such as file systems, network connections, databases, and user interfaces. This makes SystemJ capable of working with a wide variety of applications and hardware.
Integration with Other Software: SystemJ programs can interoperate with other Java code and libraries. This allows SystemJ programs to take advantage of the large ecosystem of Java libraries and frameworks.
Communication between SystemJ statements and Java statements within reactions occurs as follows:
SystemJ statements define the control flow of the program, specifying when reactions should take place. Within each reaction, Java code is executed.
SystemJ statements can pass data to Java statements using signals. The value of a signal can be retrieved in a Java statement using the
#operator.Conversely, Java statements can influence the control flow of the SystemJ program by emitting signals using the
emitstatement.
This tight integration between Java and SystemJ provides a powerful way to combine the benefits of synchronous concurrent programming (for coordination and timing) with the benefits of sequential programming (for data manipulation and interfacing with external systems).
# 7) Under what conditions channel communication would cause blocking of the execution of a clock domain and how would you mitigate it?
Answer
In SystemJ, a channel communication can cause a clock domain to block under two main circumstances:
During a Send Operation: If a clock domain is trying to send data over a channel and the receiving clock domain is not ready to receive, the sending clock domain can be blocked until the receiving clock domain is ready.
During a Receive Operation: Similarly, if a clock domain is waiting to receive data over a channel and the sending clock domain has not yet sent the data, the receiving clock domain can be blocked until the data is available.
There are a couple of ways to mitigate these blocking situations:
Buffering: By introducing a buffer in the channel, multiple send operations can be accommodated even if the receiver is not ready to receive immediately. The data gets stored in the buffer and the sending clock domain is not blocked. The receiving clock domain can then read from the buffer when it's ready.
Non-blocking or Asynchronous Communication: If the communication protocol allows, one could use non-blocking or asynchronous communication. In this model, send and receive operations return immediately, and the communication happens in the background. The sender can proceed with its work without waiting for the receiver to be ready, and vice versa. In this case, it's important to handle the situation when the receiver asks for data that's not yet available or when the sender tries to send data but the buffer (if any) is full.
It's crucial to remember that the choice of buffering and non-blocking communication would depend on the specific requirements of your system and the characteristics of the communication channel.
# 8) Illustrate how SystemJ can be used for simultaneous development of a software system and its testbed?
Answer
SystemJ is highly suited for concurrent development of a software system and its testbed due to its inherent ability to manage multiple clock domains that can run concurrently and independently. Here's a conceptual illustration of how this can be achieved:
System Under Test (SUT): Write the system that you're trying to develop using SystemJ. This is your primary application, and it's written using several clock domains, each handling different parts of your system.
Testbed: Develop another SystemJ program that serves as your testbed. This program also has its own clock domains, which are responsible for generating test signals, monitoring outputs from the SUT, and logging results.
Interface: Use channels for communication between the SUT and the testbed. Test signals are sent from the testbed to the SUT through these channels. The SUT's responses are sent back to the testbed through other channels.
Execution: Both the SUT and testbed can run concurrently. The testbed sends test inputs to the SUT, which processes the inputs and sends back outputs. The testbed can then verify the outputs against expected results and log any discrepancies.
This approach allows developers to build the system and its tests simultaneously, potentially catching issues earlier in the development process. Because both the system and testbed are written in SystemJ, they can be integrated seamlessly, and it's easier to ensure that the testbed accurately represents the operational environment of the SUT.
The ability to develop the system and testbed concurrently can lead to more efficient development, more thorough testing, and ultimately, a more robust system. However, as with any development methodology, care must be taken to manage the complexity of the concurrent development process and to ensure that the testbed accurately reflects the conditions the system will face in its operational environment.
# 9) What are the main mechanisms used to provide reactivity of SystemJ programs, clock domains and reactions and how they work.
Answer
SystemJ's reactivity, its ability to respond to external events or changes in system state, is largely managed through the use of clock domains, reactions, signals, and channels. Let's consider each of these in detail:
Clock Domains: Clock domains are the fundamental units of synchrony and concurrency in SystemJ. Each clock domain can be considered as an independent synchronous system reacting to the progression of its own logical time, defined by ticks. Clock ticks define the execution of reactions inside a clock domain and provide a notion of time for reactivity.
Reactions: Within each clock domain, reactions are blocks of code that respond to specific signals or events. These reactions are atomic within their clock domain, meaning they execute completely and uninterruptibly once started, before the tick ends. This atomicity ensures that reactions are always in a consistent state when responding to events.
Signals: Signals are the main mechanism for communication and synchronization within and across clock domains in SystemJ. They provide the means to react to events. A signal can be emitted by a reaction to signify an event, and other reactions can test for the presence or absence of a signal to react accordingly.
Channels: Channels are another mechanism for communication, primarily used for inter-clock-domain communication. Channels can send data from one clock domain to another, allowing one domain to react to data produced by another.
The reactivity of a SystemJ program is thus provided by the interplay of these elements. When an external event occurs, a signal is emitted, triggering the execution of corresponding reactions in the current or next tick. These reactions can further emit signals or send data through channels to other clock domains, propagating the reaction to the event throughout the system.
It's important to note that the management of reactivity in SystemJ is entirely deterministic and predictable due to the synchronous nature of reactions within a clock domain and the well-defined communication semantics of signals and channels. This predictability is a key advantage when designing complex, concurrent systems.
# 10) Why SystemJ programs naturally land on distributed computing platforms? What is natural minimal design entity to execute on the same processor (JVM)?
Answer
SystemJ programs naturally lend themselves to distributed computing platforms due to the inherent design of the language. Here are some of the reasons:
Concurrency and Independence: In SystemJ, concurrency is managed through clock domains, each of which can run concurrently and independently. This makes it natural to map each clock domain to a different node in a distributed system.
Synchronous and Asynchronous Execution: SystemJ supports both synchronous and asynchronous execution, corresponding to local (within clock domain) and global (across clock domains) behaviours respectively. This combination perfectly matches the requirements of distributed systems, where nodes need to execute independently (asynchronously) but often need to synchronize on specific tasks or events (synchronously).
Communication through Signals and Channels: Inter-clock-domain communication in SystemJ is handled through signals and channels, which naturally aligns with the message-passing paradigm common in distributed systems.
The natural minimal design entity to execute on the same processor or Java Virtual Machine (JVM) would be a clock domain. Each clock domain encapsulates a coherent set of behaviours that execute in lock-step, making it a logical unit of computation that can be executed on a single processor or JVM. Within a JVM, multiple clock domains can be executed in parallel using multithreading, allowing efficient utilization of multicore processors.
# 4. Synchronous programming in Esterel.
Questions:
# (a) Identify causal loops, if any, in Code 1 and fix them. Write the correct Esterel program and draw the hardware circuit generated from the correct Esterel program.
Code 1:
module M:
signal S in
present S then nothing else emit S end
end signal
end module
2
3
4
5
Answer
The provided Esterel program seems to have a causal loop with signal S. In this module, signal S is emitted if it is present. This leads to a cycle where the emission of S depends on its presence, and its presence depends on its emission, creating a causality loop.
To fix we need to have a previous state, which we can add with await tick. And then, we use pre to check the previous value. pre means that if in the previews tick the signal was not there then it's there.
module M:
signal S in
await tick;
present pre S then nothing else emit S end
end signal
end module
2
3
4
5
6
22:54 on video 15
Here is the FSM
# (b) Express the Esterel code segment in Code 2 as a single (flat) Mealy machine. Signals O1 and O2 are outputs to the environment, while S is an internal signal.
Code 2:
module M:
output O1, O2;
signal S in
[emit S
||
present S then emit O1 else emit O2 end
]
end signal
end module
2
3
4
5
6
7
8
9
Answer
First, let's understand what the Esterel code is doing:
The module M, in a parallel construct, emits an internal signal S and then checks if S is present. If S is present, it emits output signal O1, otherwise, it emits O2.
Now, let's map this behavior to a Mealy machine:
A Mealy machine is a finite-state machine which produces outputs only on transitions (rather than in states), and these outputs are a function of the current state and the input.
In our case, our states and transitions would be based on the presence or absence of the internal signal S and the resulting emissions of O1 and O2.
Since we're only dealing with one tick of execution in the Esterel program, the Mealy machine will be fairly simple. It could look something like this:
State | Input (S) | Output (O1, O2) | Next State
------------------------------------------------------
Initial | 0 | 0, 1 | Initial
Initial | 1 | 1, 0 | Initial
2
3
4
In this machine, the Input column represents the presence (1) or absence (0) of the internal signal S. The Output column represents the emitted signals O1 and O2, and the Next State column represents the state after the transition.
Note: The interpretation of this code and conversion into a Mealy machine assumes that the Esterel program starts from an initial state where neither O1 nor O2 have been emitted yet. It may vary if there are different initial conditions or if the program's execution extends over multiple ticks.
# 5. Statechart, Mealy machine, and concurrency.
Statecharts, Mealy machines, and concurrency are all related concepts in the realm of system design, programming and computation theory. Let's explore each of them:
Statecharts: A statechart (or state diagram) is a behavior diagram, a variant of the state machine, used in computer science, engineering, and related fields to describe the behavior of systems. Statecharts introduce additional notation that allows state transition diagrams to represent more complex systems, such as nested states and events, among others. Statecharts allow for visualizing the dynamic behavior of a system in response to external and internal events.
Mealy Machines: A Mealy machine is a finite-state machine where the outputs are determined by the current state and the current input. This is in contrast to a Moore machine, where the outputs are determined solely by the current state. In a Mealy machine, the actions (outputs) are associated with transitions, rather than states, leading to more compact representations of sequential systems than with Moore machines.
Concurrency: Concurrency, in the context of computing, is a property of systems where several independent tasks are executing simultaneously. These could be multiple threads within a single program, or separate processes entirely. Concurrency allows for increased efficiency and responsiveness, and can be more naturally suited to certain problems like server software, simulations, or generally anything involving multiple independent events or tasks happening at once.
Concurrency is an important aspect in statecharts and Mealy machines when they are used to model or design concurrent systems. Statecharts can represent concurrent states by splitting a state into orthogonal regions, each representing a separate thread of execution. In the context of Mealy machines, concurrency would be modeled as multiple independent machines operating simultaneously or a single machine with its state space extended to cover all possible combinations of concurrent states.
In both statecharts and Mealy machines, managing concurrency introduces additional considerations like synchronization, communication between concurrent entities, and potential issues like race conditions or deadlocks. Understanding these concepts is crucial when designing concurrent systems or interpreting statecharts or Mealy machine diagrams of such systems.
Questions:
# (a) Consider the two concurrent processes represented as a Statechart in Figure 3. Give the
resultant composition (product) as a single Statechart. Events a, b, and c are inputs from the environment.
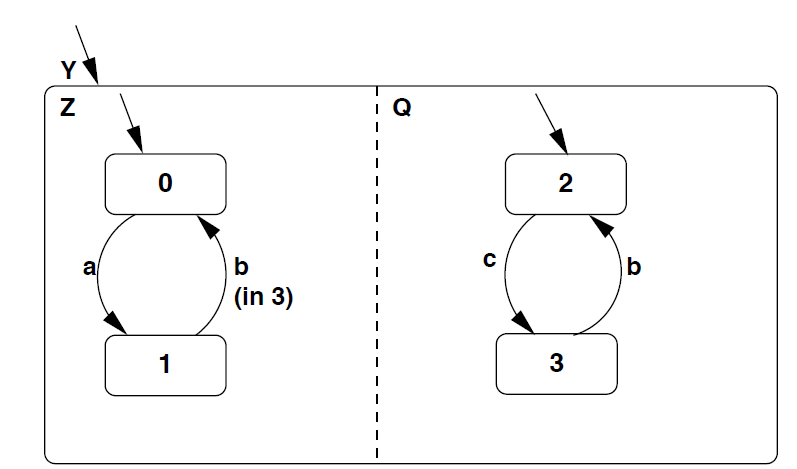
Answer
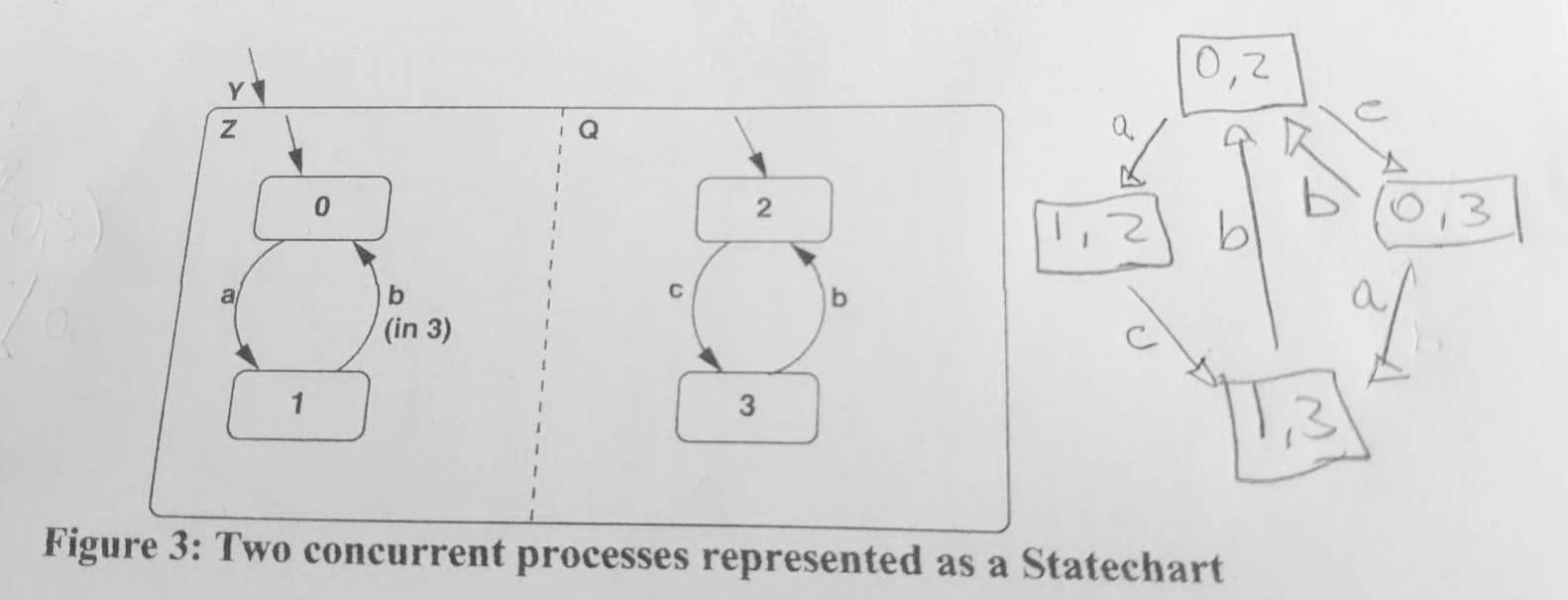
# 6. Safe State Machine, Statechart, and Mealy machine.
Questions:
# (a) Give an equivalent single (flat) Mealy machine representation for the three concurrent processes represented as a Safe State Machine (SSM) in Figure 4. A, B, and C are input signals from the environment and O is an output signal.
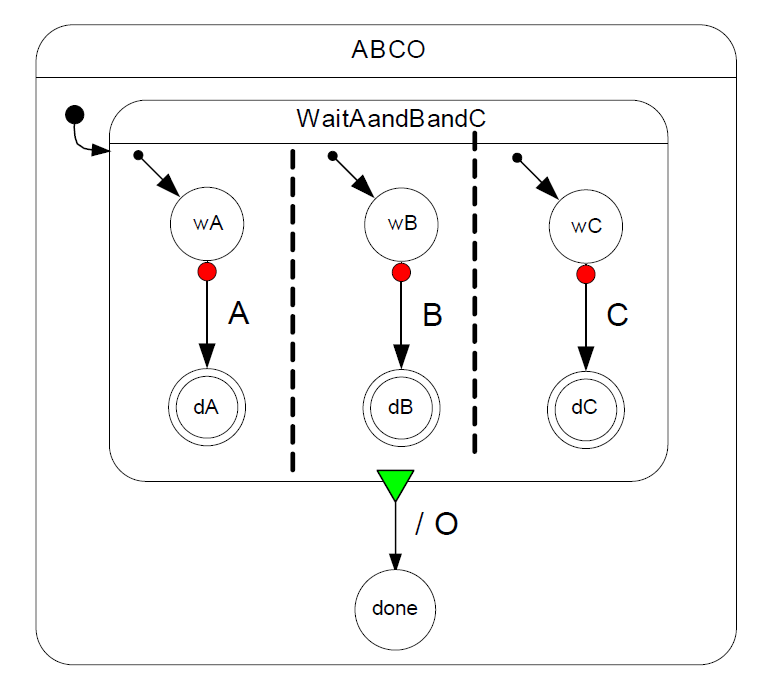
# (b) List at least two differences and two similarities between Statechart and Safe State Machine (SSM).
Answer
Statechart and Safe State Machine (SSM) are two formalism used to describe the behavior of systems. They both provide a means to represent complex state transitions and actions in a compact and visual way. However, there are some key differences and similarities between the two.
Differences:
Hierarchical States: Statechart supports hierarchical states, where a state can be divided into sub-states, allowing more complex behaviors to be expressed in a compact form. On the other hand, SSMs usually follow a flat state model where there are no sub-states.
Event Handling: Statechart also supports concurrent states, which means multiple states can be active at the same time, and it also allows for more complex event handling. In contrast, SSMs typically have only one active state at a time and their event handling might be less sophisticated.
Similarities:
Finite State Systems: Both Statechart and SSM describe systems in terms of a finite number of states and transitions between those states. This makes both of them useful for modeling discrete event systems.
State Transitions: In both Statechart and SSM, transitions between states are triggered by events. Actions can be associated with transitions, or with entry to or exit from states.
Please note that actual features and capabilities can vary depending on the specific implementation of Statechart or SSM you're using.