# C++
A list of open source C++ libraries
# C++ Essential Training - Bill Weinman
# 1. Configuring Visual Studio
# Preprocessors
First create a new Empty C++ project and Add a new existing file.
Then Select the Project (This is very important, if the file is selected It won't work)
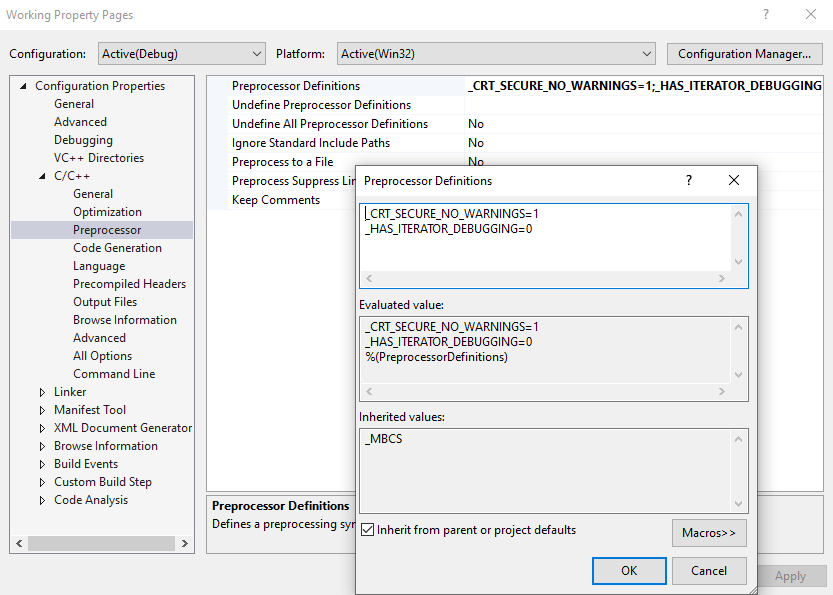
# Build clean solution shortcut on Tools > Options > Environment > Keyboard
# Install Windows SDK if not installed
https://stackoverflow.com/questions/58946328/microsoft-visual-studio-community-2019-fatal-error-c1083-cannot-open-include-f
# Running console Applications on Visual Studio
Open the Debug folder on th terminal and execute:
Thiago Souto@MSI MINGW64 ~/Documents/CppEssT/Working/Debug
$ ./working
Hello, World!
2
3
Running program cpp11 from exercise files:
# 2. Basic Syntax
# Statement
The basic syntax of C++ is very simple.
A statement is a unit of code terminated by a semicolon.
#include <cstdio>
using namespace std;
int main()
{
puts("Hello, World!");
return 0;
}
2
3
4
5
6
7
8
# Function
A function is a larger unit of code that may contain statements and expressions. A function is designed to be used or to be called by another statement. The main function is the main entry point of any C, or C++ program. Main is called by the operating system when your program first launches.
#include <cstdio>
using namespace std;
int main()
{
puts("Hello, World!");
return 0;
}
2
3
4
5
6
7
8
# Variable
A variable holds a value, or values for later use. In C++ variables must be declared before they are used. The variable may then be used to provide its value to statements and expressions later in your code.
#include <cstdio>
using namespace std;
int main()
{
const char* str = "Hello World!";
puts(str);
return 0;
}
2
3
4
5
6
7
8
9
# Anatomy of a C++ program
# Single line comment:
//
//This is a comment
#include <cstdio>
using namespace std;
int main()
{
puts("Hello, World!");
return 0;
}
2
3
4
5
6
7
8
9
# Multiline comment:
/* */
/*
This is
a
multiline
comment
*/
#include <cstdio>
using namespace std;
int main()
{
puts("Hello, World!");
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# int main()
The next thing we'll notice is this function declaration here, int main. And this is a function, and all functions are declared like this, there's a return type, which can be void in the case of functions that don't return anything, but in this case it does, you see it returns a zero.
And the main function is supposed to be declared to return an integer. Main function is actually special in C and C++. its the main entry point into the program. So, when the operating system brings up our compiled program this is where it will always begin. The operating system actually calls this, we don't call this. So the keyword main is reserved for the name of this function. And then these parentheses are normally empty these days.
#include <cstdio>
using namespace std;
int main()
{
puts("Hello, World!");
return 0;
}
2
3
4
5
6
7
8
Originally, it used to be required that they had at least two parameters, int argc and char ** argv. And what this is is the count of the arguments in this array, an array of character pointers, an array of strings that represent the arguments that are passed to the program. And you'll still see this a lot, and sometimes you'll see it like this, where there's an array of character pointers like that.
#include <cstdio>
using namespace std;
int main(int argc, char * argv[])
{
puts("Hello, World!");
return 0;
}
2
3
4
5
6
7
8
And again, you might see this, its rarely used anymore, although I guess in command line programs where there are arguments you will see it and it'll actually be used. More often than not, in modern C++ programs, you'll see this without those parameters. The main function itself, like all functions, has these curly braces, beginning on line six and ending on line nine, and oftentimes you'll see it like this, and actually I do it like this myself oftentimes. Whitespace is ignored for the most part in C and C++, so you can have this on the same line, you can actually eliminate that space, and you'll see it this way sometimes.
And so everything between these two braces is the body of the function. And so the body of the function in this case, it has two statements, a function call to a function call puts, which puts a string on the console, followed by a new line. And a statement that returns the literal value zero. We know that's an int because the return type of the function is an int like that. So the return zero, a return of some number or another, is required, and zero means success.
#include <cstdio>
You'll also notice this statement up here at line two. It starts with a pound sign and the keyword include, followed by a filename inside angle braces. So this is actually not a C++ statement. This is a directive to the pre-processor. The pre-processor will then see this pre-processor directive and it will replace that line of text with the contents of the file, in this case cstdio. The C standard I/O library. And this required because it includes the function definitions for the C standard I/O functions, which in this case puts is one of those. its a standard C function, and of course the entire C standard is part of the C++ standard, so this is actually also a standard C++ function. You'll notice this statement up here, using namespace standard, std stands for standard. This is a shortcut in C++ to support namespaces. The standard library uses the namespace called std. And so this makes it easier to use the standard library.
#include <cstdio>
using namespace std;
int main()
{
puts("Hello, World!");
return 0;
}
2
3
4
5
6
7
8
On a final note, you'll sometimes see this done in other ways, like you'll see, for example, printf, and then with a newline, because printf doesn't include that newline. So that backslash followed by the letter n represents a newline. Now, when I build and run this, you'll see it does exactly the same thing.
#include <cstdio>
using namespace std;
int main()
{
puts("Hello, World!\n");
return 0;
}
2
3
4
5
6
7
8
Or, instead of using C standard I/O, I can use iostream, which is part of the standard template library. The stl, its very C++-ish. And instead of all this I can say cout, double left-angle bracket, and Hello World, and another double left-angle bracket, and endl, which is the end of line using cout.
#include <iostream>
using namespace std;
int main()
{
cout << "Hello World!" << endl;
return 0;
}
2
3
4
5
6
7
8
# Statements and expressions
A statement is always terminated with a semicolon. An expression is anything that returns a value, whether or not the value is used. An expression may be part of a statement or it may be an entire statement.
For example, if we have an integer, x, and I assign a value to that integer, this assignment is an expression. It returns a value. In this case, it returns the value 42. And yet, it is terminated with a semicolon and it stands alone here, and so it is also a statement. In fact, this variable declaration here in x is also a statement. If I were to reply this puts with a call to printf, and we'll get into the details of printf later in this course. For now, understand that this is a statement that calls a library function printf, and it uses this string to define what is going to be printed, and the percent d is a placeholder that holds the place of an integer value, and that integer value is given here, after the comma here in the function call as an argument. And so this whole thing is a statement. And within this statement is an expression x which returns a value, all right. But the whole thing by itself is a statement. Now if I save this and run it, you see that the result is x is 42.
#include <cstdio>
using namespace std;
int main()
{
int x;
x = 42;
printf("x is %d\n", x);
return 0;
}
2
3
4
5
6
7
8
9
10
or
#include <cstdio>
using namespace std;
int main()
{
int x;
printf("x is %d\n", x = 42);
return 0;
}
2
3
4
5
6
7
8
9
A statement may include an expression or it may be an expression by itself.
# Identifiers
Identifiers provide readable names for variables, functions, labels, and defined types.

An identifier may not begin with a numeral.
Identifiers may not conflict with reserved words.
Identifiers are case sensitive.
The current C++ standard, C++ 17, reserves 73 keywords

Plus 11 alternative tokens.

- Current standards allow identifiers to be any length, although only the first 63 characters are guaranteed to be checked for uniqueness, and only the first 31 characters are guaranteed for external identifiers, so in practice you should keep your identifiers under 31 characters long.
An initial underscore character, that is, an underscore in the first position of an identifier, is commonly used for private identifiers. More than one initial underscore is generally reserved for system-level private use. So don't name your variables with two initial underscores.
_private_identifier
__system_use_only
2
# Defining Variables
Variables are strongly typed in C++ and in C. This means that the token representing a variable represents both its value, and its type.
I'm going to declare a variable, int i. The statement int i semi-colon is a variable definition, it defines the type of a variable and allocates space in the size sufficient to hold a value of that type. This variable is an integer. Currently it has no assigned value, so its value is said to be undefined. An undefined value is a very dangerous thing, so be sure to always assign a value to a variable before you use it. Once variable's defined, you may assign a value to it and use it.
#include <cstdio>
using namespace std;
int main()
{
int i;
puts("Hello World!");
return 0;
}
2
3
4
5
6
7
8
9
Once variable's defined, you may assign a value to it and use it.
This is called initializing the variable.
So if I come here and say, i equals seven. I have now assigned a value to it, and I may use it.
#include <cstdio>
using namespace std;
int main()
{
int i;
i = 7;
printf("The value is %d\n", i);
return 0;
}
2
3
4
5
6
7
8
9
10
The value is 7
Now under many circumstances you may both define and initialize a value at once. So, I can say int i equals seven like this and in one statement I am defining the variable and I am initializing it and giving it a value. And of course when I save and run this you'll notice that it still says the value is seven.
#include <cstdio>
using namespace std;
int main()
{
int i = 7;
printf("The value is %d\n", i);
return 0;
}
2
3
4
5
6
7
8
9
TIP
its usually a good idea to initialize variables as soon as possible. So I'll usually initialize it when its defined.
C++ also uses qualifiers, sometimes called modifiers, that change the behavior of variables in various ways. The qualifier becomes part of the type. So if I put the keyword const, here in front of the type int. We now have a const int, or a constant int. Const is a qualifier, short for constant. It tells the compiler that the value of this variable cannot be changed once its initialized. This is called a read-only variable.
If we try to change it the compiler will throw an error.
#include <cstdio>
using namespace std;
int main()
{
const int i = 7;
printf("The value is %d\n", i);
return 0;
}
2
3
4
5
6
7
8
9
# Pointers
Pointers are a very powerful, useful, dangerous and common data type. To really understand pointers you need to first understand how a variable works.
A variable is a typed and named location in memory. So here, this is a variable definition. Memory is allocated for a value of type integer and is associated with the name X. Here the integer value 1 is copied into the memory location associated with the integer variable X.
int x;
x = 1;
2
This one is both a definition and an assignment. Memory is allocated for an int. And the value from the variable named X is copied into the variable named Y. The variable Y now contains a separate integer in a separate memory location with the same value as the variable X. So we can see that the name of a variable is used as an index to map to a memory address and a particular associated data type.
int x;
x = 1;
int y = x;
2
3
C++ also provides a pointer type, that is a pointer to a value, as opposed to carrying the value itself. This is a pointer definition. The variable named IP is of the type pointer two INT. Here memory is allocated for a pointer. The pointer is also strongly typed. That is, the compiler associates this pointer with the INT type. We call this an integer pointer.
int *ip;
Here the address of the integer variable named X is placed in the integer pointer variable named IP. The ampersand is formally called the reference operator, but in this context its more commonly called the address of operator. It returns the address of an object suitable for assigning to a pointer.
So this statement assigns the address of X to the integer pointer IP. The integer pointer IP now points to the integer variable X.
Now its worth noting that the ampersand is also used in C++ for a special reference type that will be covered later.
int *ip;
ip = &x;
2
This assignment statement copies the value pointed to by IP, which currently points to the integer variable X, to the integer variable Y. In this context, the asterisk is called the pointer dereference operator. its used to get the value pointed to by the pointer. You can of course also change IP to point to a different variable.
int *ip;
ip = &x;
y = *ip;
2
3
Example:
#include <cstdio>
using namespace std;
int main()
{
int x = 7;
int y = 42;
int *ip = &x;
printf("The value of x is %d\n", x);
printf("The value of y is %d\n", y);
printf("The value of ip is %d\n", *ip);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
The value of x is 7
The value of y is 42
The value of ip is 7
2
3
# References
The C++ reference type is a lot like a pointer but with some significant differences.
Now when I build and run the program below, you'll see that we have sevens all around.
The value what's pointed at by ip, see 'cause we took the address of x, and here we have a reference, an integer reference named y, which refers to x.
So y in this case is a reference. The variable y is a reference. And you can use y, just like you can use any other int, but its value is always the value of x.
#include <cstdio>
using namespace std;
int main()
{
int x = 7;
int *ip = &x;
int &y = x;
printf("The value of ip is %d\n", *ip);
printf("The value of x is %d\n", x);
printf("The value of y is %d\n", y);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
The value of ip is 7
The value of x is 7
The value of y is 7
2
3
So, if I change x, and save and run. You see that y is five, so is what's pointed at by ip.
#include <cstdio>
using namespace std;
int main()
{
int x = 7;
int* ip = &x;
int& y = x;
x = 5;
printf("The value of ip is %d\n", *ip);
printf("The value of x is %d\n", x);
printf("The value of y is %d\n", y);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
The value of ip is 5
The value of x is 5
The value of y is 5
2
3
4
And, if I change y, this is the interesting thing. Now x changes as well, as does the de-referenced pointer value.
So, there's two major differences between a pointer and a reference.
First, you do not use an asterix to de-reference a reference. So you see, down here in line 15, I'm using y, just as I use x, as if it is not anything special. Second, there's no syntax for changing a reference. Once the reference is defined, it cannot be changed. When I came up here and changed y to equal 42, it didn't make y no longer refer to x, it simply changed x.
#include <cstdio>
using namespace std;
int main()
{
int x = 7;
int* ip = &x;
int& y = x;
y = 42;
printf("The value of ip is %d\n", *ip);
printf("The value of x is %d\n", x);
printf("The value of y is %d\n", y);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
The value of ip is 42
The value of x is 42
The value of y is 42
2
3
So, while a pointer is a variable of type pointer, I can assign it to point at something else. So, lets say for example, I have a variable z and I change ip to equal the address of z, and we can always just add another one of these down here for z, so we can keep track of that as well. And now when I save and run this, you'll notice that what's pointed at by ip is now 73, which is the value of z. And y is still equal to x.
#include <cstdio>
using namespace std;
int main()
{
int x = 7;
int* ip = &x;
int& y = x;
y = 42;
int z = 73;
ip = &z;
printf("The value of ip is %d\n", *ip);
printf("The value of x is %d\n", x);
printf("The value of y is %d\n", y);
printf("The value of z is %d\n", z);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
The value of ip is 73
The value of x is 42
The value of y is 42
The value of z is 73
2
3
4
So a reference is strictly speaking not a variable. It can not be redefined or refer to a different value, once its been declared, it will always refer to the same variable.
References are used a lot in C++, especially in functions and classes. You'll see many examples of this in the rest of the course.
C, notably, does not have references. This is an exclusive feature of C++.
# Primitive Arrays
The primitive array type is commonly called a C array because its inherited from the C language.
A primitive type is a type that's defined as part of the language, the array is a primitive type.
Primitives are essential tools for building derived types, including structures and classes.
An array is a fixed sized container for elements with a common type.
This is a definition of an array of integers with room for five values.
At this point the array is uninitialized so each of the five integer values are undefined.
int ia[5];
Arrays are indexed with integer values. The first element is always number zero.
So an array with a size of five will have elements numbered zero through four. The value in the square brackets is the index.
This means that we are assigning a value to the element at index zero.
This assigns the value one to the first element of the array.
int ia[5];
ia[0] = 1;
2
Array elements may also be accessed as if the array were a pointer. This statement has exactly the same effect as the previous statement.
This is a very common practice, so you'll need to recognize it when you see it.
int ia[5];
ia[0] = 1;
*ia = 1;
2
3
This defines an integer pointer and assigns the address of the array to the pointer.
Notice that you don't need the address of operator to get an array's address.
This is because an array may be accessed as if it were a pointer.
int ia[5];
ia[0] = 1;
*ia = 1;
int *ip = ia;
2
3
4
This assigns the value two to the first element of the array. Because the pointer was initialized to the address of the array it is pointing to the first element.
int ia[5];
ia[0] = 1;
*ia = 1;
int *ip = ia;
*ip = 2;
2
3
4
5
You can increment the pointer and it will point to the second element.
In C++ pointers are strongly typed so they know the size of what they point to.
When you increment a pointer, it always increments by the size of the object or type it is defined with.
int ia[5];
ia[0] = 1;
*ia = 1;
int *ip = ia;
*ip = 2;
++ip;
2
3
4
5
6
So this assigns the value three to the second element of the array.
int ia[5];
ia[0] = 1;
*ia = 1;
int *ip = ia;
*ip = 2;
++ip;
*ip = 3;
2
3
4
5
6
7
This is another common technique in C++, here we're incrementing a pointer and using it at the same time.
its just a shortcut for the separate increment in assignment of the previous two statements.
int ia[5];
ia[0] = 1;
*ia = 1;
int *ip = ia;
*ip = 2;
++ip;
*ip = 3;
*(++ip) = 4;
2
3
4
5
6
7
8
You may also initialize an array using an initializer list. This both declares the array and assigns the values one, two, three, four, and five to the five elements of the array.
This is a new feature in C++, so it may not work on older compilers. its very convenient and you'll see it a lot in newer code.
int ia[5] = { 1, 2, 3, 4, 5 };
The primitive array is a fundamental part of the C++ language and you'll see it often. its useful as a basis for more complex structures and classes, as well as on its own.
# Primitive strings
A primitive string is a special case of an array.
This is different from the stl string class. The primitive string is often called a C string.
#include <cstdio>
using namespace std;
int main()
{
char s[] = "String";
printf("String is: %s\n", s);
return 0;
}
2
3
4
5
6
7
8
9
String is: String
Now, what's interesting is that string as I said, is a special case of a primitive array. So I can also do exactly the same thing, like this. And when I save and run this, you see that we get exactly the same result.
#include <cstdio>
using namespace std;
int main()
{
char s[] = { 'S', 't', 'r', 'i', 'n', 'g', 0 };
printf("String is: %s\n", s);
return 0;
}
2
3
4
5
6
7
8
9
String is: String
A C string is simply a primitive array of characters terminated with a zero. This is sometimes also called a null terminated string.
You can access the individual characters just as you would in an array.
Using a for look, we are accessing this character array as a normal array, right there on line eleven and also on line ten in the loop. So you can see that a primitive string or a C string exactly the same as a C array.
#include <cstdio>
using namespace std;
int main()
{
char s[] = "String";
printf("String is: %s\n", s);
for (int i = 0; s[i] != 0; ++i) {
printf("char is % c\n", s[i]);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
String is: String
char is S
char is t
char is r
char is i
char is n
char is g
2
3
4
5
6
7
You can even do this with a pointer, like this.
Character pointer (char * cp), and what's pointed at is true, which means its not null (*cp;). And you can increment the pointer (++cp), just like that, and I'm going to initialize the pointer to be equal to the address of the array (char * cp = s;) which you will call The address of the C array can just be taken from its token without the AddressOf operator. And then, down here we're going to de reference the pointer. (*cp)
So, when I run this, of course we get exactly the same result. But this time we're de referencing the array through a pointer, rather then through the index.
#include <cstdio>
using namespace std;
int main()
{
char s[] = "String";
printf("String is: %s\n", s);
for (char * cp = s; *cp; ++cp) {
printf("char is % c\n", *cp);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
String is: String
char is S
char is t
char is r
char is i
char is n
char is g
2
3
4
5
6
7
You can even use a range based loop, like this. Range based loops are new feature of C++ 11. And this is extremely easy way, and I do still have to check for zero, so if c is equal to zero, we will break out of the loop. And when I save and run this of course we get exactly the same result.
#include <cstdio>
using namespace std;
int main()
{
char s[] = "String";
printf("String is: %s\n", s);
for (char c : s) {
if (c == 0) break;
printf("char is % c\n", c);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
String is: String
char is S
char is t
char is r
char is i
char is n
char is g
2
3
4
5
6
7
So, the combination of C arrays and pointers is both common and powerful. An array is structure of variables of the same type, stored contiguously and indexed by an integer value. And because the array is guaranteed to be stored contiguously, at least the primitive array, its also easy to iterate with pointers. And a primitive string is simply a specific application of a primitive array.
# Conditionals
A conditional statement allows you to run one block of code or another, based on a conditional expression. C++ has two basic forms of conditional statements, both inherited from C, if else and the ternary conditional operator.
# if
#include <cstdio>
using namespace std;
int main()
{
int x = 42;
int y = 7;
if (x > y) {
puts("Condition is true");
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
Condition is true
# else
#include <cstdio>
using namespace std;
int main()
{
int x = 42;
int y = 72;
if (x > y) {
puts("Condition is true");
}
else {
puts("Condition is false");
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Condition is false
# else if
#include <cstdio>
using namespace std;
int main()
{
int x = 42;
int y = 72;
if (x > y) {
puts("Condition is true");
} else if ( y > 12 ) {
puts("else if is true");
} else {
puts("Condition is false");
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
else if is true
TIP
In C++ logical values are represented as integers. Zero is false and any non-zero value is true.
#include <cstdio>
using namespace std;
int main()
{
int x = 42;
int y = 72;
printf("value is %d\n", x > y);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
value is 0
#include <cstdio>
using namespace std;
int main()
{
int x = 42;
int y = 72;
printf("value is %d\n", x < y);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
value is 1
Any non-zero value is true, and any zero value is false.
#include <cstdio>
using namespace std;
int main()
{
int x = 42;
int y = 72;
if ( 0 ) {
puts("Condition is true");
} else {
puts("Condition is false");
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Condition is false
#include <cstdio>
using namespace std;
int main()
{
int x = 42;
int y = 72;
if ( 142 ) {
puts("Condition is true");
} else {
puts("Condition is false");
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Condition is true
C++ also provides a ternary conditional operator. If you've never used C or any of the C-based languages before this might seem a little bit weird, but its actually quite common in C, C++, and in likewise derived languages that are derived from a family of languages.
If I say printf the greater value is percent d, then I can say x is greater than y and a question mark, and x and a colon and y. So the way this works is the condition comes first, the question mark and the colon are considered the ternary conditional operators, so its ternary because it has three operands.
The first operand is to the left of the question mark.
The second operand is in between the question mark and the colon.
And the third operand is after the colon, so that's what makes it a ternary operator.
And its conditional because that first operator is a condition. And the second operator is returned if the condition is true. And the third operator is returned if the condition is false. Basically when I run this, it'll say that the greater value is 72.
#include <cstdio>
using namespace std;
int main()
{
int x = 42;
int y = 72;
printf("The greater value is %d\n", x > y ? x : y);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
The greater value is 72
All of these conditionals are inherited from C and are exactly the same in both languages. There's one more type of conditional, a multi-way switch.
# The branching conditional
C++ provides a special multiway conditional using the switch statement. This is a feature from the C language.
So, the way that switch works is it tests the value its passed to it, and then it tests it against each of these case statements, and when it finds the one that matches, in this case iTHREE, it branches execution to the line after that case statement.
#include <cstdio>
using namespace std;
int main()
{
const int iONE = 1;
const int iTWO = 2;
const int iTHREE = 3;
const int iFOUR = 4;
int x = 3;
switch (x) {
case iONE:
puts("one");
break;
case iTWO:
puts("two");
break;
case iTHREE:
puts("three");
break;
case iFOUR:
puts("four");
break;
default:
puts("default");
break;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
three
Now you notice this break statement here. Break is a branching statement, which breaks out of a block. And you'll notice that switch has all of these case statements in a block. And so if I were to take this break out, it would actually fall through and print both three and four.
Finally there is a default option, so if the x is not matched by one of the case statements, lets say I make it 42, when I run this, you'll notice it says default. The default is optional. If that was not there, and I ran this, it would simply break all the way out.
Switch can be very handy in cases where you need to select a condition from a list of possibilities.
TIP
The case statement requires a constant, so you'll need to take special care to use the proper type for this purpose.
# Looping with while and do
The basic loop control in C++ is the while loop. The while loop tests a condition at the top of the loop, and there's also a version that tests the condition at the bottom of the loop.
You notice I initialize an array with five elements, an integer array with five integers, one, two, three, four, and five, I initialize an integer variable called i at zero, and then in the while loop, I test while i is less than five. So the while loop has a condition in parentheses, and that condition is tested for while its true, the while loop will continue running, and when that condition gets to false, the while loop will stop. And so here, you'll notice that at the end of the block, I increment i, and so at some point, i will no longer be less than five, and the while loop will stop.
#include <cstdio>
using namespace std;
int main()
{
int array[] = { 1, 2, 3, 4, 5 };
int i = 0;
while(i < 5) {
printf("element %d is %d\n", i, array[i]);
++i;
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
element 0 is 1
element 1 is 2
element 2 is 3
element 3 is 4
element 4 is 5
2
3
4
5
We can also use break to get out of the loop. So when I compile and run this, you see we get element zero is one, element one is two, and when it sees that i is equal to two here, it simply breaks out of the loop.
break branches execution to after the end of the block.
if ( i == 2 ) break;
There's another control called continue, and I'm going to put this inside a little block here, and I'm going to say ++i and continue. So in this case what happens, what continue does, continue branches back to the beginning of whatever control structure its in, and in this case, its in a while loop. Continue is usually used in a loop, and it goes back up to the top and executes that control again. In this case, what it'll do is it will simply skip the printf and this increment, it has its own increment, and it'll continue after that. So it'll simply skip element number two, which is the three here, and if I compile and run, you'll notice it says element zero, element one, and element three, its skipping two, and that's what the continue statement does.
#include <cstdio>
using namespace std;
int main()
{
int array[] = { 1, 2, 3, 4, 5 };
int i = 0;
while(i < 5) {
if ( i == 2 ) {
++i;
continue;
}
printf("element %d is %d\n", i, array[i]);
++i;
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
element 0 is 1
element 1 is 2
element 3 is 4
element 4 is 5
2
3
4
Now instead of testing at the top, we can test at the bottom, so I'm going to use the cut here on the Mac, which is Command + X, or Control + X on a PC, I'm going to put in a do instead, and I'm going to put that condition at the end with the semicolon there after the condition. And what this does is this puts the test at the end of the loop instead of at the beginning of the loop. And so when I run this, you'll see that its running exactly as we expect, but in this case, its not testing that while at the top, its testing that while at the bottom. You won't see the do while as often as you will see the regular while loop with the test at the top, but you will see it occasionally, and there are circumstances where its convenient, and so its good to know about it.
#include <cstdio>
using namespace std;
int main()
{
int array[] = { 1, 2, 3, 4, 5 };
int i = 0;
do {
printf("element %d is %d\n", i, array[i]);
++i;
} while(i < 5)
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
element 0 is 1
element 1 is 2
element 2 is 3
element 3 is 4
element 4 is 5
2
3
4
5
The while loop is, of course, inherited from C, and its the same in both languages. While is a fundamental control in C++. Do while is used less frequently, but its still important to understand.
# Iterating with for
C++ provides two versions of the for loop. One is inherited from C, and the other is unique to C++.
Now a for loop is unique, in that it has three different types of controls inside the parentheses after the keyword for.
And the first one is generally used for initializing. This happens before the loop begins and its only executed ones.Then there's a semicolon. And then there's a conditional expression which must be satisfied in order for the loop to continue running. Just like in the while loop. So many people call this the wild clause.
And then there's a control that happens after the block of code has been executed but before the while control, before this conditional expression is evaluated again. And so this is often used for incremental a variable.
And so here we have in the first control, this is before the loop, we declare an integer, and we initialize it to zero, then we have while that integer is less than five, and then we increment that integer. And then inside the block, all we need is one statement. So you can see how this is very convenient. And this is a very, very common loop to see in C++ and also in C.
#include <cstdio>
using namespace std;
int main()
{
// basic for loop
for ( int i = 0; i < 5; ++i ) {
printf("i is %d\n", i);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
i is 0
i is 1
i is 2
i is 3
i is 4
2
3
4
5
You'll often see it used for increment iterating through an array. And so if I have a character string, for example, need my closing quote there. Then I can say int i equals zero.
And I can test for the end of the string like this (string[i]). Because we know that a character string in C++ is simply an array of characters terminated by a zero.
And we know that the integer value zero is false as a condition. This is just testing until we get to the end of the string. And I can printf, I can say, c for the character, and I can say string sub i like that.
#include <cstdio>
using namespace std;
int main()
{
char string[] = "abcdefg";
// basic for loop
for ( int i = 0; string[i]; ++i ) {
printf("i is %c\n", string[i]);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
And now we build and run you'll notice it'll print out every element of that array a, b, c, d, e, f, g, and it stops. Because there is that eighth element of the array, there's seven letters here, that eighth element of the array is an integer zero. And so, that is evaluated as false in our while condition and the loop ends.
i is a
i is b
i is c
i is d
i is e
i is f
i is g
2
3
4
5
6
7
This is also often used with a pointer. So we can say, character pointer, and its equals the beginning of the string (char * cp = string;).
And we're testing while that character points to something that is not zero (*cp).
And we increment the pointer like this (++cp).
And now instead of dereferencing the string like that (string[i]), we can simply dereference it like that (*cp). What's pointed out by our pointer and when I run this, we'll get exactly the same result.
#include <cstdio>
using namespace std;
int main()
{
char string[] = "abcdefg";
// basic for loop
for (char * cp = string; *cp; ++cp) {
printf("i is %c\n", *cp);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
i is a
i is b
i is c
i is d
i is e
i is f
i is g
2
3
4
5
6
7
So the for loop is a fundamental control in C++ and you can see here that there's a number of ways that its commonly used. its inherited from C, and its exactly the same in both languages. its incredibly powerful and useful. And while it might look a little cryptic at first, once you get to know it, you'll find many, many uses for it. There's also another form of the for loop exclusive to C++.
# Ranged-based for loop
Beginning with the C++11 version of C++, there's a new range-based for loop. This gives C++ a simple way of iterating over the elements of a container, an operation that used to take a bit more code.
So, it goes like this for int i in array, and we have that colon there (int i : array), which tells us that we're iterating through a container and the container's the right of the colon and what each element of the container is going to be put in is the left of the colon.
So, each element of the array will be placed in this integer i during the for loop, and so, I can simply say printf i is %d for an integer, like that.
#include <cstdio>
using namespace std;
int main()
{
int array[] = { 1, 2, 3, 4, 5 };
for ( int i : array ) {
printf("i is %d\n", i);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
i is 1
i is 2
i is 3
i is 4
i is 5
2
3
4
5
Now, our range-based for loop is a compiled time feature, and so, even though this is a simple c array and its not terminated in any way, and we're not testing for the number of elements or anything like that because this happens at compiled time, the compiler knows the size of the array, and so, that makes this very, very simple and concise.
So, of course, it also works great with strings, so we can say, character array s equals and string, and then, instead of this integer i, we can say character c and say c is a character. Like this. And instead of array here, of course, change that to s, 'cause that's our container and now, when I build and run this, you'll notice that we get every element of that array.
#include <cstdio>
using namespace std;
int main()
{
char s[] = "String";
for ( char c : s ) {
printf("c is %c\n", c);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
So, there's six characters and then there's the zero terminator, the null terminator, and so, that is also printed.
c is S
c is t
c is r
c is i
c is n
c is g
c is
2
3
4
5
6
7
If we want to not print that null terminator, we can simply say if c is equal to a zero, break, and it will not print that null terminator. So, the break and continue controls work as expected in the range-based for loop.
#include <cstdio>
using namespace std;
int main()
{
char s[] = "String";
for ( char c : s ) {
if ( c == 0 ) break;
printf("c is %c\n", c);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
c is S
c is t
c is r
c is i
c is n
c is g
2
3
4
5
6
In fact, instead of this separate declaration, we can simply put the literal right there in the range-based for loop, and we can build and run this and it works exactly the same way because its a compiled time feature, it knows what to do with that.
#include <cstdio>
using namespace std;
int main()
{
for ( char c : "String" ) {
if ( c == 0 ) break;
printf("c is %c\n", c);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
c is S
c is t
c is r
c is i
c is n
c is g
2
3
4
5
6
The range-based for loop is very powerful and its a powerful and useful addition to C++ beginning with C++11. It provides simple and effective solution for iterating over the elements of a container.
It works just as well with native arrays, with STL vectors and strings, initializer lists, and anything that supports sequential iterators.
As new code is written in C++ and older code is updated or retired, the range-based for loop is becoming very common.
# Using stdout
The standard output stream is how text is displayed on the console.
C++ also has an object-oriented class for displaying output on the console. The cout class is part of the standard C++ library, and it works quite a bit differently than puts or printf, which are part of the standard C library. In fact, cout works quite a bit differently from other objects and classes or anything else in C++.
#include <iostream>
using namespace std;
int main()
{
cout << "Hello, World!" << endl;
return 0;
}
2
3
4
5
6
7
8
And you'll notice right away that instead of including cstdio, the standard I/O library from C, I'm including iostream, which is part of the standard template library, the STL.
cout is an STL class and it overloads the bitwise left shift operator(<<), which is this two left angle brackets. It overloads this operator to send a stream of characters to the standard output stream.
its very common in C++ and you'll see it used a lot. cout can be very convenient.
in fact, if I come down here, I can string other things together. I can say 2 * 7 right in there and I'll put in a space here. And I can even add another string, another string. I can string together as many strings as I want to, including this endl object, which ends the line.
#include <iostream>
using namespace std;
int main()
{
cout << "Hello, World! " << 2 * 7 << " Another String" << endl;
return 0;
}
2
3
4
5
6
7
8
Hello, World! 14 Another String
So, its convenient, and how things are formatted are defined by how each type or class overloads the bitwise left shift operator.
If you have some experience in C++ or you've seen some C++ code, you'll notice that while I often use puts or printf instead of cout, many other people use cout almost exclusively.
These are two different approaches to the same problem. So, how do I choose which one to use? Many people maintain that cout should be always preferred because its more object-oriented or more C++-ish, than puts and printf.
# 3. Data types
# Overview of Data Types
C++ is a strongly typed language. This means that every value has a specific type. The meaning of a value is largely determined by its type. A data type determines both the size and the interpretation of a value.
Primitive types are those basic types that are used in building other compound types. Primitives in C++ include integers for representing integer and numerical values, floating points for representing real numerical values, and a Boolean type for representing true and false values.
Primitive types:
- Integer types
- Floating point types
- Boolean type
Compound types serve as containers for primitives and other types. An array is a contiguous sequential set of objects of the same type. Arrays are very powerful, flexible, and have very low overhead. They're also the basis of C-strings and the C++ STL container classes.
int x[5] = { 1, 2, 3, 4, 5 };
Although C++ has no primitive string type a null terminated array of characters is a special case, often called a C-string and its treated as a string in many contexts.
char s[] = "this is a string";
A structure is a sequential set of objects of various types. A structure may contain scalars, arrays, and even other structures and classes.
struct x {
int a;
float b;
char c[25];
};
2
3
4
5
C++ classes are based on C-structures.
Technically, a class is a structure that defaults to private membership.
In practice, a class is a structure that contains function members as well as data members.
class x {
int a;
float b;
char c[25];
public:
int getvalue() const;
void setvalue( int v );
};
2
3
4
5
6
7
8
A union is a set of overlapping objects. This allows a single compound object to hold objects of different types at different times overlapping the same memory space.
union x {
int a;
float b;
char c[25];
};
2
3
4
5
A pointer is a reference to an object of a given type. The pointer itself typically holds the address of the object to which is points. Pointers are strongly typed in C++. The type of a pointer is used as the type when its dereferenced and its also used to determine the size of increments, decrements, and arithmetic operations on the pointer.
int x = 42;
int * px = &x;
printf("x is %d\n", *px);
2
3
A reference is like a pointer but with different semantics. References are immutable, once defined they cannot be changed to refer to a different object and references are accessed as aliases without any syntactic indication that its a reference. This allows for silent side effects and should be used with great care.
int x = 42;
int & rx = x;
printf("x is %d\n", rx);
2
3
with great care. C++ provides a number of fundamental data types that may be used or extended for many purposes.
# Integer types
Integer types are simple, fundamental data types for representing integer values; whole number with no fractional part. The integer types include char, characters, C-H-A-R. Int, which is short for integer. Short int, long int, and long long int.
- char
- short int
- int
- long int
- long long int
# char
The character type is defined as the minimum size necessary to contain a character. On most modern systems its 8 bits.
The character type may be signed or unsigned by default. That is, on some systems it may a signed value, on other systems it may be unsigned. You cannot count on a character being one or the other. The only thing you can count on is that it will hold a character.
All the other integer types are signed unless modified with the unsigned keyword.
# short int
The short int type is the smallest natural size of an integer for the target processor. It may be the same as int. On most modern desktop systems its 16 bits.
# int
The int type is the natural size of an integer for the target processor. On most modern systems its 32 bits.
# long int
Long int is at the size of an integer. its often double the size of int. On most modern systems its either 32 or 64 bits.
# long long int
Long long int is at least the size of a long int. It may be double the size of long int. On most modern systems its 64 bits.
For the signed types, the most significant bit is a sign bit.
Unsigned types are available with the unsigned modifier. These are the same size as the signed types, but they don't set aside a bit for the sign.
- unsigned char
- unsigned short int
- unsigned int
- unsigned long int
- unsigned long long int
If your usage requires an integer of a specific size, the C standard int header, cstdint, provides types in these specific widths. 8 bits, 16 bits, 32 bits, and 64 bits. Both signed and unsigned.
# Integer sizes
Integer types are simple, fundamental data types for representing integer values.
Now, I'm going to go ahead and build and run this. And you notice that it reports the number of bits for each of these types.
And the way this works is I've got this constant expression here, which is the number of bits in a byte, which is eight, and here for each of these types, I'm multiplying the result of size of, times the number of bits and bytes. Size of returns the number of bytes. So, I want to get bits, so I've got to multiply it by eight.
#include <cstdio>
using namespace std;
// a byte is 8 bits
constexpr size_t byte = 8;
int main()
{
printf("sizeof char is %ld bits\n", sizeof(char) * byte);
printf("sizeof short int is %ld bits\n", sizeof(short int) * byte);
printf("sizeof int is %ld bits\n", sizeof(int) * byte);
printf("sizeof long int is %ld bits\n", sizeof(long int) * byte);
printf("sizeof long long int is %ld bits\n", sizeof(long long int) * byte);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
sizeof char is 8 bits
sizeof short int is 16 bits
sizeof int is 32 bits
sizeof long int is 32 bits
sizeof long long int is 64 bits
2
3
4
5
Now, that's a literal value that's being assigned to an integer, and that's a literal integer value. I can say that this is an octal by saying zero two two three which will give us that same value of 47. And that zero in front of the literal integer value makes it not decimal, but octal instead. Octal is base eight.
#include <cstdio>
using namespace std;
int main()
{
int x = 0223;
printf("x is %d\n", x);
return 0;
}
2
3
4
5
6
7
8
9
10
11
x is 147
You can also get base 16 or hexadecimal by saying zero x, and I think its nine three will give us that same one 47 value, and see, x is one 47. So, that zero x nine three is hexadecimal or base 16, and of course, you can put a couple zeros in front of that, and you still get the same result.
#include <cstdio>
using namespace std;
int main()
{
int x = 0x0093;
printf("x is %d\n", x);
return 0;
}
2
3
4
5
6
7
8
9
10
11
x is 147
For binaries 0b is the key to be placed in front of the value.
I can suffix the value with a U, and that'll make it unsigned, and so I can build and run, and there's that.
I can suffix it with an L for long, and so, now, I need to say long here, and I need to say ld there, and when I build and run, now, we have a long value, or I can actually use two Ls for long long, and you see I did it there, I forgot the int, and I'm not sure, I think I can put two Ls here, and it'll still work there. And so that's a long long value.
int x = 147U;
printf("x is %d\n", x);
long int x = 147L;
printf("x is %ld\n", x);
long long int x = 147LL;
printf("x is %lld\n", x);
2
3
4
5
6
7
8
So C++ provides a full selection of integer types, in many sizes, both signed and unsigned.
# Fixed-size integers
The size of fundamental integer types may vary from system to system. The standard provides specifically sized integers for applications where the precise size of an integer is critical.
If you need actual particular sizes there is a standard header with standard type depths that will give you that result.
So this is the standard int stdint.
And I'll load that up and you'll see its very similar we have these types int8, int16, int32 these all exist in this stadard int header cstdint.
#include <cstdio>
#include <cstdint>
using namespace std;
// a byte is 8 bits
constexpr size_t byte = 8;
int main()
{
printf("sizeof int8_t is %ld bits\n", sizeof(int8_t) * byte);
printf("sizeof int16_t is %ld bits\n", sizeof(int16_t) * byte);
printf("sizeof int32_t is %ld bits\n", sizeof(int32_t) * byte);
printf("sizeof int64_t is %ld bits\n", sizeof(int64_t) * byte);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
sizeof int8_t is 8 bits
sizeof int16_t is 16 bits
sizeof int32_t is 32 bits
sizeof int64_t is 64 bits
2
3
4
And when I build and run this go ahead and do that now you'll notice that these types are specific sizes. So int8 is exactly eight bits. Int16 is 16 bits, int32 is 32 bits and int64 is 64 bits. And you'll notice they each have this _t at the end of them that says that its a type. its a convention in C and C++ for your type defs to have that _t after them so that you know what they are.
#include <cstdio>
#include <cstdint>
using namespace std;
// a byte is 8 bits
constexpr size_t byte = 8;
int main()
{
printf("sizeof uint8_t is %ld bits\n", sizeof(uint8_t) * byte);
printf("sizeof uint16_t is %ld bits\n", sizeof(uint16_t) * byte);
printf("sizeof uint32_t is %ld bits\n", sizeof(uint32_t) * byte);
printf("sizeof uint64_t is %ld bits\n", sizeof(uint64_t) * byte);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
sizeof uint8_t is 8 bits
sizeof uint16_t is 16 bits
sizeof uint32_t is 32 bits
sizeof uint64_t is 64 bits
2
3
4
You notice that they are exactly the same size. We have signed and we have unsigned of specific widths. Now these integers are guaranteed to be the same size on every system where they're supported and they are part of the standard and so you can expect them to be supported on most if not all systems.
C++ provides this separate set of standardized integers of guaranteed size for applications where the precise size or range of an integer is critical.
# Floating Point types
C++ provides the common basic floating point types.
#include <cstdio>
using namespace std;
// a byte is 8 bits
constexpr size_t byte = 8;
int main() {
float f;
double df;
long double ldf;
printf("size of float f is %ld bits\n", sizeof(f) * byte);
printf("size of double float df is %ld bits\n", sizeof(df) * byte);
printf("size of long double float ldf is %ld bits\n", sizeof(ldf) * byte);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
size of float f is 32 bits
size of double float df is 64 bits
size of long double float ldf is 64 bits
2
3
Sizes may not be the same on your system unless you're running a very similar system to mine. Says size of float is 32 bits, size of double float is 64 bits, and the size of the long double float is 128 bits. Now its worth noting that the long double float is not actually 128 bits, that's just how much space its taking up in the variable. Actually, only 80 bits are used because that's the IEEE standard. And there are some systems, notably Visual C++ on a PC, that do not have the 80-bit long double float available, its still 64 bits. So you'll see variations on different systems.
Now literal floating point numbers, if I come down here at the end, and then I'll say f equals 500.0, that putting in a decimal point makes that literal, a floating point literal instead of an integer literal. And so I can print this value with printf. And when I build and run, you'll see that the value of f is 500 and it gives it a certain amount of precision, and you can specify that in printf. We'll get to that in a moment.
#include <cstdio>
using namespace std;
int main() {
float f;
f = 500.0;
printf("value of f is %f\n", f);
return 0;
}
2
3
4
5
6
7
8
9
10
11
value of f is 500.000000
What's interesting here, you can also use scientific notation, you can say five e two and build and run that, and you can also get that value.
f = 5e2;
value of f is 500.000000
And so being able to specify in scientific notation like that, for instance if you wanted to say five e 20, and build and run, you'll notice that you get a much larger number.
f = 5e20;
value of f is 500000010020438671360.000000
much larger number. And you'll notice also here that after a certain number of digits, its no longer accurate, and that's an important thing to understand about floating point numbers. That a floating point number gives you a certain amount of scale, so you specify very, very large numbers but the precision is only to a certain number of digits, and that's a function of the size of the variable.
So if I do the same thing with df, and I'll put an l in here, and call this df here, now when I build and run this, you notice that I get more precision, I get more significant digits of precision.
#include <cstdio>
using namespace std;
int main() {
double df;
df = 5e20;
printf("value of lf is %f\n", df);
return 0;
}
2
3
4
5
6
7
8
9
10
11
value of lf is 500000000000000000000.000000
Now what's important to understand here, and I'm going to go ahead and use df for this as well, and if I say that this equals 0.1 plus 0.1 plus 0.1, right, and I run this, you'll notice that it says that its 0.3, but if I say if df is equal to 0.3, puts True, else puts False, and when I run this, you'll notice that the answer is False. So 0.1 plus 0.1 plus 0.1 should be equal to 0.3, right? But its not.
And the reason for that is this precision thing. Floating point numbers give you scale, but its at the expense of precision.
#include <cstdio>
using namespace std;
int main() {
double df;
df = .1 + .1 + .1;
if (df == 0.3) {
puts("True");
}
else {
puts("False");
}
printf("value of lf is %f\n", df);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
False
value of lf is 0.300000
2
And if I come out here and I say 1.10 like that (printf("value of f is %1.10lf\n", df)😉, and we give ourselves ten digits of precision in what we're printing out, and I run this, you'll see that it still says that its all zeros, but if I give it 20 digits of precision ("value of f is %1.20f\n", df);, notice that it starts getting different out there.
#include <cstdio>
using namespace std;
int main() {
double df;
df = .1 + .1 + .1;
if (df == 0.3) {
puts("True");
}
else {
puts("False");
}
printf("value of lf is %1.20f\n", df);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
False
value of lf is 0.30000000000000004441
2
different out there. Now I can even do this with the long double, which is 80 bits of precision, right? And in order for this to print out correctly, I need to put in the capital L there for the long double float (%1.20Lf). And now when I build and run, you notice its still False, and we're still getting a variation in those last few digits.
#include <cstdio>
using namespace std;
int main() {
long double ldf;
ldf = .1 + .1 + .1;
if (ldf == 0.3) {
puts("True");
}
else {
puts("False");
}
printf("value of ldf is %1.20Lf\n", ldf);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
False
value of f is 0.30000000000000004441
2
So it maybe possible to represent very large and very small values using floating point types, but precision of these types is always limited.
these types is always limited. On most modern systems, a 32-bit float has precision at about seven digits, and a 64-bit double float has precision to about 16 digits, and on the long double, as in on this one, with the 80-bit IEEE format, the precision varies but its still not infinite. So its important to understand this when you're deciding to use floating point numbers instead of integers.
Now C++ provides the standard floating point types. While its possible to represent very large, very small numbers with these types, it is at the expense of accuracy.
If precision is important, as in the case of accounting, you'll want to use an integer type instead.
# Characters and strings
In C + + the fundamental string type is an array of characters terminated with a null value. This is sometimes referred to as a C-string or a null terminated string to distinguish it from object orientated string types.
The character type is technically an integer of a size suitable for holding a character which is eight bits on most systems.
A string is an array of these characters terminated with a null value or a zero.
#include <cstdio>
using namespace std;
int main() {
char cstring[] = "String";
printf("The string is: %s\n", cstring);
for( unsigned int i = 0; cstring[i]; i++) {
printf("%02d: %c\n", i, cstring[i]);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
So, this six character string takes up seven values in the array. That's this string right here ( char cstring[] = "String"; ). And, if I go ahead and build and run this. You see that our printf is printing the string is and the string.
And, this four loop here is printing out all of the values of the string not including the null. And, you'll notice that the wow condition in the four loop is testing for a non zero value of the character in the array.
The string is: String
00: S
01: t
02: r
03: i
04: n
05: g
2
3
4
5
6
7
The literal string here, this is a special case in C and C + + where a set of characters inside of quote marks is actually a C-string. And, so its a literal C-string. its an array of characters, including a zero character, a null byte at the end of the array.
char cstring[] = "String";
We get exactly the same result here, if instead of the array, we use a character pointer.
And, you'll notice if I try to build this I'll get an error. C + + does not allow conversion from string literal to character pointer, has to be a const character pointer.
char * cstring = "String";
error
And, so now when I build it, it succeeds and if I build and run, you see we get exactly the same result.
Because, the character pointer can be used as if it were an array.
const char * cstring = "String";
Now, you'll notice also that this is const character pointer. its a pointer to a const character, not a const pointer. And so, if I were to change this, you notice that it works, I can build and run this. And, our string is now foo, I've actually changed the pointer to point to something else.
That's because the pointer itself is not const, its the character that its pointing to is const.
#include <cstdio>
using namespace std;
int main() {
const char * cstring = "String";
cstring = "foo";
printf("The string is: %s\n", cstring);
for( unsigned int i = 0; cstring[i]; i++) {
printf("%02d: %c\n", i, cstring[i]);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
The string is: foo
00: f
01: o
02: o
2
3
4
And, if I put a const here instead after the asterisk, now you notice I try to build this and I get an error.
Can not assign because the pointer is const-qualified.
const char * cstring = "String";
So, you'll see this a lot, this const character and what that means is that its a pointer to an array that you can not change.
const char * cstring = "String";
One final thing I want to show you here, concatenating literal strings is done by simply placing them next to each other without any operator in between. And, so I'll put in space and foo there and you'll notice when we run this we get string space foo, like that. So, that's how you concatenate literal strings in C + +. Very simple.
#include <cstdio>
using namespace std;
int main() {
const char* cstring = "String" " foo";
printf("The string is: %s\n", cstring);
for (unsigned int i = 0; cstring[i]; i++) {
printf("%02d: %c\n", i, cstring[i]);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
The string is: String foo
00: S
01: t
02: r
03: i
04: n
05: g
06:
07: f
08: o
09: o
2
3
4
5
6
7
8
9
10
11
So, C-strings are a very simple form of strings, much simpler than the string class provided by the C + + STL for circumstances where you don't need the power of the object oriented strings.
C-strings are simple, small, fast and are very commonly used in C + +. In fact, the STL string class is based upon a C-string.
So, the STL string class will be covered later in this course, but this is C-strings for now.
# Character-escape sequences
Some characters in C++ have special meaning or are otherwise not normally accessible with normal C++ language parameters. Escape sequences are used to access these characters.
Each escape sequences begins with a single backslash character, like that, and for example if I wanted a quote mark, a double quote within this string that has double quotes on either side of it. And so these double quotes, this one and the one at the beginning, these are what make this a literal string but if I want to include a double quote I simply put in a backslash first on the double quote.
And you'll see when I build and run, that I get that double quote within the string down there.
#include <cstdio>
using namespace std;
int main()
{
puts("Hello, World! \" ");
return 0;
}
2
3
4
5
6
7
8
Hello, World! "
I can do the same, of course, with a single quote mark. There we have a single quote.
puts("Hello, World! \' ");
And if I want a backslash character, I simply escape it first with its own backslash escape so I have two backslashes.
puts("Hello, World! \\ ");
If I build and run you see we get a backslash in the string.
Or if I want just any character whatsoever I can put in the hexadecimal ASCII for that and the hexadecimal 40 happens to be the at sign, so there's the at sign if I wanted to use it to, for example, build an email address, or something with an at symbol in it.
puts("Hello, World! \x40 ");
Hello, World! @
There are also non-graphic characters, so for example, if I had this string Hello, World in here again, and in between here I wanted to put in a new line to have this show up on two separate lines I can do that with backslash n, and of course we've used this in other places when we're using printaf, in this chapter, and so when I run this you see we get Hello, World on two separate lines.
puts("Hello, World! \nHello, World!");
Hello, World!
Hello, World!
2
We can also get a tab with \t, and that'll put in some number of spaces.
puts("Hello, World! \tHello, World!");
Hello, World! Hello, World!
Or any Unicode character whatsoever. So if I take these out again and I go over here. Any Unicode character with its hexadecimal Unicode code point, so backslash u, and then the hexadecimal digits say 03bc, and I'll get a Greek letter mu.
puts("Hello, World! \u03bc");
Hello, World! ?
error on the character
Now you may not see a mu on your system, if your system doesn't support Unicode, so obviously for Unicode code points, you need to have a system that supports Unicode all the way through the build chain and all the way out to the console.
This is a full table of the standard character escape sequences. Most of these you'll rarely if ever use, like form feeds and audible bell, things like that, we don't use those very often anymore. These are from the days of line printers and adm3 terminals and such. But they're all there, and they're all in the standard and so its useful to know about them.
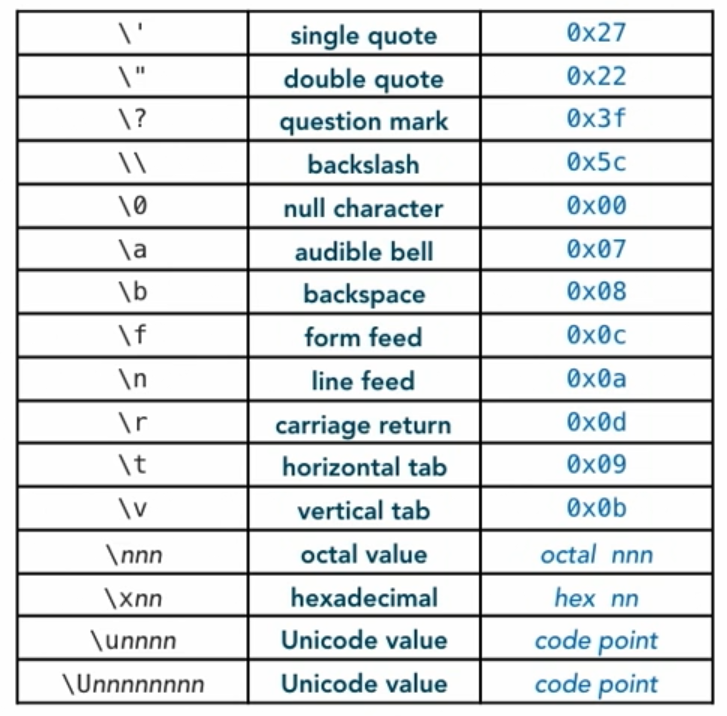
Character escape sequences are commonly used to provide special characters in string constants that may not otherwise be accessible on the keyboard or due to conflicts in the language.
# Qualifiers
Qualifiers are used to adjust qualities of an object or variable. There are two types of qualifiers in C++. CV qualifiers and storage duration qualifiers.
This is an example of a variable declaration with qualifiers. In this example the const and static keywords are qualifiers. They tell the compiler that this variable will be immutable, that's the const qualifier, and that it will have static storage duration.
const static int i = 42;
There are two types of qualifiers. CV qualifiers where CV stands for constant and volatile.
const marks a variable as read-only or immutable. Its value cannot be changed once its been defined.
volatile marks a variable that may be changed by another process. This is generally used for threaded code.
And mutable is used on a data member to make it writable from a const qualified member function.
Storage duration qualifiers are used to define the duration or lifetime of a variable. By default a variable defined within a block has automatic lifetime. Lifetime is the duration of the block. There is no qualifier for this because its the default. There used to be an auto-qualifier but it was rarely used so the keyword has been repurposed.
Static variables have life beyond the execution of a block. Static variables live for the duration of the program. Static variables are commonly used for keeping state between usages of a given function or method. Static variables are stored globally, even if they are stored in a class. By default a variable defined outside of any block is static.
Register variables are stored in processor registers. This can make them faster and easier to access and operate on. This qualifier is taken as a suggestion by the compiler. The compiler may or may not actually store the variable in a register.
Extern variables are defined in a separate translation unit and are linked with your code by the linker step of the compilation process.
| CV Qualifiers | Storage Qualifiers |
|---|---|
| const | static |
| volatile | register |
| mutable | extern |
If we come down here to the main function, I'll build and run this, you see it says, the integer is 42.
#include <cstdio>
using namespace std;
class S {
public:
int static_value() {
static int x = 7;
return ++x;
}
};
int func() {
int x = 7;
return ++x;
}
int main() {
int i = 42;
printf("The integer is %d\n", i);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
The integer is 42
Now if I mark this as a const integer, save it and run it the result is the same. The difference here is that I cannot change the value.
If I say i = 7 and build and run, you notice that I get an error, cannot assign the variable i with const-qualified type const int.
#include <cstdio>
using namespace std;
class S {
public:
int static_value() {
static int x = 7;
return ++x;
}
};
int func() {
int x = 7;
return ++x;
}
int main() {
const int i = 42;
i = 7;
printf("The integer is %d\n", i);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
1>------ Build started: Project: Working, Configuration: Debug Win32 ------
1>qualifiers.cpp
1>C:\Users\Thiago Souto\Desktop\VUEPRESS\MASTERS\docs\Resources\C++\Ex_Files_CPlusPlus_EssT\Exercise Files\Chap03\qualifiers.cpp(19,10):
error C3892: 'i': you cannot assign to a variable that is const
1>Done building project "Working.vcxproj" -- FAILED.
========== Build: 0 succeeded, 1 failed, 0 up-to-date, 0 skipped ==========
2
3
4
5
6
If I take out the const qualifier and build and run you'll notice that it works just fine and it says, the integer is 7.
The integer is 7
Now if instead I say the integer is what's returned by this func function up here, now it'll say, again when I build and run, that the integer is eight this time because you notice that it gets incremented.
#include <cstdio>
using namespace std;
class S {
public:
int static_value() {
static int x = 7;
return ++x;
}
};
int func() {
int x = 7;
return ++x;
}
int main() {
int i = 42;
i = func();
printf("The integer is %d\n", i);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
The integer is 8
What's interesting here is if I run this a few times, you'll notice that each time the result is still eight because this is an automatic storage variable here inside the function and its lifetime is the block of the function, so each time through the function it gets initialized again to seven.
#include <cstdio>
using namespace std;
class S {
public:
int static_value() {
static int x = 7;
return ++x;
}
};
int func() {
int x = 7;
return ++x;
}
int main() {
int i = 42;
i = func();
printf("The integer is %d\n", i);
i = func();
printf("The integer is %d\n", i);
i = func();
printf("The integer is %d\n", i);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
The integer is 8
The integer is 8
The integer is 8
2
3
But if I make it static, now when I run this several times you'll notice that we get a different result each time because the lifetime of the variable is now the lifetime of the entire program. It no longer gets re-initialized each time the function is called.
#include <cstdio>
using namespace std;
class S {
public:
int static_value() {
static int x = 7;
return ++x;
}
};
int func() {
static int x = 7;
return ++x;
}
int main() {
int i = 42;
i = func();
printf("The integer is %d\n", i);
i = func();
printf("The integer is %d\n", i);
i = func();
printf("The integer is %d\n", i);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
The integer is 8
The integer is 9
The integer is 10
2
3
Now there's an important distinction here and you'll notice this class S. So if instead of all of this, I say, S a and S b and S c and then print out the result of this static value member function three times and do it once for each of these. Now when I build and run this, you'll notice that I get a different value each time.
#include <cstdio>
using namespace std;
class S {
public:
int static_value() {
static int x = 7;
return ++x;
}
};
int func() {
static int x = 7;
return ++x;
}
int main() {
S a;
S b;
S c;
printf("a.static_value() is %d\n", a.static_value());
printf("b.static_value() is %d\n", a.static_value());
printf("c.static_value() is %d\n", a.static_value());
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
a.static_value() is 8
b.static_value() is 9
c.static_value() is 10
2
3
What's interesting here is when you define a static variable inside a member function in a class, that means that, that one variable will be the same for every instance of the class because again, static means the lifetime of the program. And so that static variable is exactly the same storage unit no matter how many times you instantiate the class. No matter how many objects you create from the class, each one of those objects is using the exact same variable.
So when I call a static value and then I call b static value, that same x is getting incremented each time. So its important to notice this distinction.
Obviously in a function there's only ever going to be one instance of that function, or you're not making objects with separate variable names out of that function. But you do with a class, and so that static variable you need to realize is good for the life of the program and it is shared by every object that is created by that class.
So qualifiers are used to control the quality of variables. Some of these like const and static you'll use frequently. Others are good to know about for when you need them or when you see them in code.
# References
C++ references are very much like pointers but with different rules and semantics.
I'll start by declaring a variable int i = 5. And I'm going to declare a reference to that variable. Going to say int ir = i. So that's the integer reference that is referring to the variable i with the value of five, and now I'm going to say ir = 10 and I'm going to go ahead and print it.
What I'm going to print is i not ir. And now you'll notice when we build and run here that i is 10 and that's because I assigned 10 to the reference which is referring to i.
#include <cstdio>
using namespace std;
int main() {
int i = 5;
int & ir = i;
ir = 10;
printf("i is %d\n", i);
return 0;
}
2
3
4
5
6
7
8
9
10
i is 10
So a reference works very much like a pointer but with some significant differences.
The syntax of assigning a reference is different and does not involve using the address of operator.
The syntax of getting the value referred to by a reference does not involve the value of or de-reference operator.
You cannot refer to the reference itself. That is you cannot take a reference of a reference. You cannot have a pointer to a reference and you cannot have an array of references.
The reference cannot be null, cannot be un-initialized, and cannot be changed to refer to another variable.
So if we look at our example here, you see that I'm assigning this variable i to this reference and so now this reference, its like an alias to the variable itself. I can use it without any de-reference operator and when I change its value, its value is the same as what's referred to.
So i and ir, from the perspective of how they're used, are exactly the same and refer to exactly the same memory space and exactly the same variable.
#include <cstdio>
using namespace std;
int main() {
int i = 5;
int & ir = i;
ir = 10;
printf("i is %d\n", ir);
return 0;
}
2
3
4
5
6
7
8
9
10
i is 10
Now lets look at a common usage because this kind of usage here is actually good for explaining but, it doesn't really have much use in the real world.
But lets say that I have a function, and this function returns a reference to an integer and it takes as its argument a reference. And it operates on that so its, return ++i so its going to take that integer, and its going to increment that value and return that value.
But everything involved here is references right? And so now I'm going to come down here after my printf and I'm going to say printf, lets put it in quotes f() is %d f(i) like that. And then I'm going to printf i again. We can do it this way.
#include <cstdio>
using namespace std;
int & f(int & i) {
return ++i;
}
int main() {
int i = 5;
int & ir = i;
ir = 10;
printf("i is %d\n", i);
printf("f() is %d\n", f(i));
printf("i is %d\n", i);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Now when I run this you'll notice a couple of things are happening here.
f returns 11 because it takes a reference to i and it increments it and it returns a reference to that. So its returning i and i is 10 here and then it increments it to 11 and so f is returning 11. And now i is also 11 when we print i after its passed to the function.
i is 10
f() is 11
i is 11
2
3
So while we can see that this is useful where you don't want to have to copy some object of unknown size for every function call, and that's frankly what its used for a lot, the downside is that unless you look at the function's signature, there's no way by just looking at this here, there's no way of knowing that it has side effects. That i is actually affected and that's a serious downside.
In fact what I can do here is I can say = 42 and now when we run it, i is actually changed to 42 because you see this is returning a reference to something that is referenced when its passed in. So these side effects are not obvious.
#include <cstdio>
using namespace std;
int & f(int & i) {
return ++i;
}
int main() {
int i = 5;
int & ir = i;
ir = 10;
printf("i is %d\n", i);
printf("f() is %d\n", f(i) = 42);
printf("i is %d\n", i);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
i is 10
f() is 42
i is 42
2
3
Now I can mitigate a lot of these side effects by doing this.
#include <cstdio>
using namespace std;
const int & f(const int & i) {
return ++i;
}
int main() {
int i = 5;
int & ir = i;
ir = 10;
printf("i is %d\n", i);
printf("f() is %d\n", f(i) = 42);
printf("i is %d\n", i);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
1>------ Build started: Project: Working, Configuration: Debug Win32 ------
1>qualifiers.cpp
1>C:\Users\Thiago Souto\Desktop\VUEPRESS\MASTERS\docs\Resources\C++\Ex_Files_CPlusPlus_EssT\Exercise Files\Chap03\qualifiers.cpp(5,15): error C3892: 'i': you cannot assign to a variable that is const
1>C:\Users\Thiago Souto\Desktop\VUEPRESS\MASTERS\docs\Resources\C++\Ex_Files_CPlusPlus_EssT\Exercise Files\Chap03\qualifiers.cpp(13,36): error C3892: 'f': you cannot assign to a variable that is const
1>Done building project "Working.vcxproj" -- FAILED.
========== Build: 0 succeeded, 1 failed, 0 up-to-date, 0 skipped ==========
2
3
4
5
6
Now you'll notice a few things are happening here. A lot of what I'm trying to do here is no longer allowed.
This assigning the 42, that's no longer allowed, because what f returns now is a const reference. So its const-qualified and it can't be changed.
In fact even inside of the function, I now need to say int local _i = i and now passing the reference is almost useless.
#include <cstdio>
using namespace std;
const int & f(const int & i) {
int _i = i;
return ++_i;
}
int main() {
int i = 5;
int & ir = i;
ir = 10;
printf("i is %d\n", i);
printf("f() is %d\n", f(i));
printf("i is %d\n", i);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
And now when I run this you'll see that my side effect is no longer there.
i is 10
f() is 11
i is 10
2
3
So my recommendation is to use pointers when you want to be able to have side effects because then its obvious as you're using it, that there are pointers involved and that side effects are possible.
Use references only where you can use const as I have here. But you need to be aware that not everyone agrees with my opinion on this.
There's a lot of code out there that use non const references including quite a bit of the standard template library.
So you just need to be conscious that this effect is possible and look at your function signatures, especially on library code.
References are very powerful and they're very common in C++ and we'll be using references quite a bit and you will gain much more experience with them, over the course of taking this Course.
# Structured data
The struct type provides a way to aggregate a fixed set of data members into a single object.
In C++ the struct type is expanded to also include function members. That usage is covered in the classes section of the companion course, C++ Advanced Topics. In this movie, we'll be dealing with struct as an aggregate data type by far its most common usage.
And we'll see down here starting on line five, we have a struct called employee and it has three data members, integer and two C strings. And down here on line 12, we declare a variable, thiago of type employee which is our structure and we initialize it using an initializer list.
Now the initializer list is a fairly new feature in C++ 11. its widely enough deployed though that you'll start seeing it commonly used and its just worlds easier than declaring the structure and then initializing each of the members individually.
And down here on line 14, we have a printf, which prints out each of the members of the structure, each of the members of the instance of the structure that's named thiago and its using these member operators, the dot is a member operator and that's how we get at the members of the structure.
#include <cstdio>
using namespace std;
struct Employee {
int id;
const char * name;
const char * role;
};
int main() {
Employee thiago = { 36, "Thiago", "Boss" };
printf("%s is the %s and has id %d\n",
thiago.name, thiago.role, thiago.id);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
And so when I build and run you'll see it says thiago is the boss and has ID 36.
Thiago is the Boss and has id 36
I can also declare a pointer to the structure. I can say employee pointer and we'll just call this E and I can give it the address of joe. And now instead of each of these I can say E and use the pointer remember operator -> instead of just the member operator. And e like that, and I'll just copy and past that over here. And now when I build and run you see, we get exactly the same result.
#include <cstdio>
using namespace std;
struct Employee {
int id;
const char * name;
const char * role;
};
int main() {
Employee thiago = { 36, "Thiago", "Boss" };
Employee * e = &thiago;
printf("%s is the %s and has id %d\n",
e->name, e->role, e->id);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
Thiago is the Boss and has id 36
So the ability to create data structures using struct is a fundamental tool in C++ and as we'll see later is also the basis of classes and objects.
# Bit fields
Bit fields provide the ability to pack multiple values into less space then they would normally use.
Notice this structure here has a number of elements for bool values and one unsigned int.
And then if you look here there's a colon after the identifier. And each of these bools has a number one and then the unsigned int has four. That's how many bits are set aside for that particular value. So these are bit fields.
And each of these bools only takes one bit, which is all you really need for a bool. its either zero or one. And numberofChildren we set aside four bits for that, presuming that not very many people have more than sixteen children.
#include <cstdio>
using namespace std;
struct preferences {
bool likesMusic : 1;
bool hasHair : 1;
bool hasInternet : 1;
bool hasDinosaur : 1;
unsigned int numberOfChildren : 4;
};
int main() {
struct preferences homer;
homer.likesMusic = true;
homer.hasHair = false;
homer.hasInternet = true;
homer.hasDinosaur = false;
homer.numberOfChildren = 3;
printf("sizeof int: %ld bits\n", sizeof(int) * 8);
printf("sizeof homer: %ld bits\n", sizeof(homer) * 8);
if(homer.likesMusic) printf("homer likes music\n");
if(homer.hasHair) printf("homer has hair\n");
if(homer.hasInternet) printf("homer has net\n");
if(homer.hasDinosaur) printf("homer has a dino\n");
printf("homer has %d children\n", homer.numberOfChildren);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
And so when I build and run this, you'll see the size of homer is 32-bits. See here a size of an integer is 32-bits, and the size of the homer structure is 32-bits (in the windows case 64-bits). Homer likes music, he has net, and he has three children. He does not have hair, and so this "if" is false. And he does not have a dinosaur, so that one is false. You can see we're testing the Boolean fields and displaying the number from the four bit integer field.
sizeof int: 32 bits
sizeof homer: 64 bits
homer likes music
homer has net
homer has 3 children
2
3
4
5
There are no guarantees about very much about bit fields. The language does not guarantee any particular bit ordering. It does not guarantee byte packing. How your data is stored in memory is highly dependent upon the target architecture.
And as I said, while this took up 32-bits here on this Mac, on the PC I tested it was 64-bits. This is especially an issue if you store packed data in a file and then expect to read it on a different machine.
its also worth noting the bit fields can be a source of trouble in concurrent, or threaded programming, because all the bits in a unit must be read and written at the same time.
# Enumerations
The C++ enumerated type called enum, is a useful thing.
What's interesting about enum is that while it looks syntactically like a type, and here you'll see it on line seven and eight. While it looks syntactically like a type and its even referred to as a type, its not really a type.
Enumerated names actually work more like constants than like types and they make a great alternative to pre- processor constants.
Enums are by default based on the int type as a fundamental type and you may change that to a different scaler-editor type here, using uint8 (uint8_t) to save space and you specify that after the colon, and if you don't specify that, it'll simply default to an int and everything will work fine.
Here I have card suit and I have specified four possible values, spade, heart, diamond, and club { SPD, HRT, DIA, CLB }.
And now I can use those identifiers and they will translate into an integer that can then be compared with this value, to see if its the same.
You can also specify particular values for your constants, for your enum. So here I have, ace equals one, deuce equals two, jack equals 11, and queen and king will be 12 and 13, because by definition, they go sequentially from the last specified number { ACE = 1, DEUCE = 2, JACK = 11, QUEEN, KING }.
// cards.cpp by Bill Weinman <http://bw.org/>
// version for C++ EssT 2018
#include <cstdio>
#include <cstdint>
using namespace std;
enum card_suit : uint8_t { SPD, HRT, DIA, CLB };
enum card_rank : uint8_t { ACE = 1, DEUCE = 2, JACK = 11, QUEEN, KING };
constexpr const char * aceString = "Ace";
constexpr const char * jckString = "Jack";
constexpr const char * queString = "Queen";
constexpr const char * kngString = "King";
constexpr const char * deuString = "Deuce";
constexpr const char * spdString = "Spades";
constexpr const char * hrtString = "Hearts";
constexpr const char * diaString = "Diamonds";
constexpr const char * clbString = "Clubs";
struct card {
uint8_t rank : 4;
uint8_t suit : 4;
};
card deck[52] = {
{ ACE, SPD }, { DEUCE, SPD }, { 3, SPD }, { 4, SPD }, { 5, SPD }, { 6, SPD }, { 7, SPD },
{ 8, SPD }, { 9, SPD }, { 10, SPD }, { JACK, SPD }, { QUEEN, SPD }, { KING, SPD },
{ 1, HRT }, { 2, HRT }, { 3, HRT }, { 4, HRT }, { 5, HRT }, { 6, HRT }, { 7, HRT },
{ 8, HRT }, { 9, HRT }, { 10, HRT }, { 11, HRT }, { 12, HRT }, { 13, HRT },
{ 1, DIA }, { 2, DIA }, { 3, DIA }, { 4, DIA }, { 5, DIA }, { 6, DIA }, { 7, DIA },
{ 8, DIA }, { 9, DIA }, { 10, DIA }, { 11, DIA }, { 12, DIA }, { 13, DIA },
{ 1, CLB }, { 2, CLB }, { 3, CLB }, { 4, CLB }, { 5, CLB }, { 6, CLB }, { 7, CLB },
{ 8, CLB }, { 9, CLB }, { 10, CLB }, { 11, CLB }, { 12, CLB }, { 13, CLB }
};
void print_card( const card & c ) {
if(c.rank > DEUCE && c.rank < JACK) {
printf("%d of ", c.rank);
} else {
switch(c.rank) {
case ACE:
printf("%s of ", aceString);
break;
case JACK:
printf("%s of ", jckString);
break;
case QUEEN:
printf("%s of ", queString);
break;
case KING:
printf("%s of ", kngString);
break;
case DEUCE:
printf("%s of ", deuString);
break;
}
}
switch(c.suit) {
case SPD:
puts(spdString);
break;
case HRT:
puts(hrtString);
break;
case DIA:
puts(diaString);
break;
case CLB:
puts(clbString);
break;
}
}
int main() {
long int count = sizeof(deck) / sizeof(card);
printf("count: %ld cards\n", count);
for( card c : deck ) {
print_card(c);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
Now starting on line 10, we have some constants. These are constant character strings, constant C strings, that we'll be using later on.
constexpr const char * aceString = "Ace";
constexpr const char * jckString = "Jack";
constexpr const char * queString = "Queen";
constexpr const char * kngString = "King";
constexpr const char * deuString = "Deuce";
constexpr const char * spdString = "Spades";
constexpr const char * hrtString = "Hearts";
constexpr const char * diaString = "Diamonds";
constexpr const char * clbString = "Clubs";
2
3
4
5
6
7
8
9
And then we have a structure. And this structure, you'll notice I'm using bit fields, because I can and it potentially saves space. Rank and suit each take up four bits and so this will all fit into eight bits, if the compiler is capable of doing that. And if not, it still works.
struct card {
uint8_t rank : 4;
uint8_t suit : 4;
};
2
3
4
And now we have our deck of cards. We have 52 cards and each of these cards uses the card structure and so its two values and we're using our enums here. Ace of spades, deuce of spades, three of spades, four of spades, et cetera. And if we look back up here at our enums, ace is always one, deuce is always two, the jack, queen, king are 11, 12, and 13 and we have spade, heart, diamond, and club and we don't really care what numbers are assigned to those, so we don't specify them.
card deck[52] = {
{ ACE, SPD }, { DEUCE, SPD }, { 3, SPD }, { 4, SPD }, { 5, SPD }, { 6, SPD }, { 7, SPD },
{ 8, SPD }, { 9, SPD }, { 10, SPD }, { JACK, SPD }, { QUEEN, SPD }, { KING, SPD },
{ 1, HRT }, { 2, HRT }, { 3, HRT }, { 4, HRT }, { 5, HRT }, { 6, HRT }, { 7, HRT },
{ 8, HRT }, { 9, HRT }, { 10, HRT }, { 11, HRT }, { 12, HRT }, { 13, HRT },
{ 1, DIA }, { 2, DIA }, { 3, DIA }, { 4, DIA }, { 5, DIA }, { 6, DIA }, { 7, DIA },
{ 8, DIA }, { 9, DIA }, { 10, DIA }, { 11, DIA }, { 12, DIA }, { 13, DIA },
{ 1, CLB }, { 2, CLB }, { 3, CLB }, { 4, CLB }, { 5, CLB }, { 6, CLB }, { 7, CLB },
{ 8, CLB }, { 9, CLB }, { 10, CLB }, { 11, CLB }, { 12, CLB }, { 13, CLB }
};
2
3
4
5
6
7
8
9
10
Now I have a function called print card and you notice that it uses a switch statement which we learned about in the previous chapter. And we're using an if, if these are numeric values. In other words, if its greater than deuce and less than jack, then we print out the numeric value. Otherwise, if its an ace, we print out the ace string, jack, queen, king, et cetera.
void print_card( const card & c ) {
if(c.rank > DEUCE && c.rank < JACK) {
printf("%d of ", c.rank);
} else {
switch(c.rank) {
case ACE:
printf("%s of ", aceString);
break;
case JACK:
printf("%s of ", jckString);
break;
case QUEEN:
printf("%s of ", queString);
break;
case KING:
printf("%s of ", kngString);
break;
case DEUCE:
printf("%s of ", deuString);
break;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
And then we print out the suit and again we're using a case statement. In the case statements, we're simply comparing them against our enums, this is what enum is really good at.
switch(c.suit) {
case SPD:
puts(spdString);
break;
case HRT:
puts(hrtString);
break;
case DIA:
puts(diaString);
break;
case CLB:
puts(clbString);
break;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
And I simply have a main function that goes through the deck and prints each one using the print card function.
int main() {
long int count = sizeof(deck) / sizeof(card);
printf("count: %ld cards\n", count);
for( card c : deck ) {
print_card(c);
}
return 0;
}
2
3
4
5
6
7
8
9
And when I build and run, you'll notice that it prints our entire deck of cards, spades, hearts, diamonds, and clubs, 52 cards, ace of spades, deuce of spades, et cetera, through diamonds and clubs.
count: 52 cards
Ace of Spades
Deuce of Spades
3 of Spades
4 of Spades
5 of Spades
6 of Spades
7 of Spades
8 of Spades
9 of Spades
10 of Spades
Jack of Spades
Queen of Spades
King of Spades
Ace of Hearts
Deuce of Hearts
3 of Hearts
4 of Hearts
5 of Hearts
6 of Hearts
7 of Hearts
8 of Hearts
9 of Hearts
10 of Hearts
Jack of Hearts
Queen of Hearts
King of Hearts
Ace of Diamonds
Deuce of Diamonds
3 of Diamonds
4 of Diamonds
5 of Diamonds
6 of Diamonds
7 of Diamonds
8 of Diamonds
9 of Diamonds
10 of Diamonds
Jack of Diamonds
Queen of Diamonds
King of Diamonds
Ace of Clubs
Deuce of Clubs
3 of Clubs
4 of Clubs
5 of Clubs
6 of Clubs
7 of Clubs
8 of Clubs
9 of Clubs
10 of Clubs
Jack of Clubs
Queen of Clubs
King of Clubs
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
For many uses, constants may be a better choice, if you need something other than a scale or value.
But enum is often a great alternative to pre-processor constants and for some uses the enum type can be very handy for grouping scaler constants together when they have a common usage.
# Unions
A union is a data structure that allows you to use the same memory space for different types.
// union.cpp by Bill Weinman <http://bw.org/>
#include <cstdio>
#include <cstdint>
using namespace std;
union ipv4 {
uint32_t i32;
struct {
uint8_t a;
uint8_t b;
uint8_t c;
uint8_t d;
} octets;
};
int main()
{
union ipv4 addr;
addr.octets = { 192, 168, 73, 42 };
printf("addr is %d.%d.%d.%d is %08x\n",
addr.octets.a, addr.octets.b, addr.octets.c, addr.octets.d, addr.i32 );
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
addr is 192.168.73.42 is 2a49a8c0
So, this is a common use for unions, providing different representations of the same data.
In this case, we have a union with two members and they take up the same space.
One member is this 32 bit integer and the other is this 32 bit structure, which is separated out into 4 separate 8 bit octets.
Unions may be used to conserve space in data structures, reusing space for various purposes that are not needed in the same context.
They are also sometimes used for crude polymorphism, like my example here, but you must be careful about type checking.
A union may be a convenient solution for some civil cases like this high pv4 address, for more complex uses you may consider using a class.
# Defining types with typedef
Typedef may be used to provide an alias for a type name. This can be handy in instances where a type declaration becomes cumbersome, or it may vary on different target systems.
In this file I'm going to declare a couple of typedefs here.
I'm going to say typedef unsigned char and I'm going to call it points_t.
its traditional to name our typedefs with this underscore t at the end of them. So, when we use them, we know that its a typedef, and I'm going to do it again. Call this one rank_t or rank type.
I'm going to declare a structure and I'll use both of these, points_t and we'll call that one p and rank_t, and you'll notice that my completion is listing those and that's kind of useful.
And we'll come out here and we'll declare a variable.
// working.cpp by Bill Weinman <http://bw.org/>
#include <cstdio>
using namespace std;
typedef unsigned char points_t;
typedef unsigned char rank_t;
struct score {
points_t p;
rank_t r;
};
int main()
{
score s = { 5, 1 };
printf("score s has %d points and rank of %d\n", s.p, s.r);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
score s has 5 points and rank of 1
So, providing a simple alias like this for the points_t and the rank_t can be convenient in providing architecture independent types.
In fact, the u-int types in the Standard Integer Library are created with typedefs just like these.
The typedef facility can be very convenient for specifying cumbersome type definitions and machine dependent types.
This can be handy when dealing with complex template types like we'll see some examples of later in this course.
# The void type
The void type has special meaning in C++, its used to specify lack of value for function parameters and function returns.
Here in this example we notice that we have a function here that returns void and takes void as an argument, as a return type void means that the function does not return a value, and so no return statement is allowed or required.
// void-type.cpp by Bill Weinman <http://bw.org/>
#include <cstdio>
using namespace std;
void func ( void ) {
puts("this is void func ( void )");
}
int main() {
puts("calling func()");
func();
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
And so if I were to say here return 7, like this you notice notice that I'll get an error when I try to build this, it says "void function should not return a value" and it will not compile.
// void-type.cpp by Bill Weinman <http://bw.org/>
#include <cstdio>
using namespace std;
void func ( void ) {
puts("this is void func ( void )");
return 7;
}
int main() {
puts("calling func()");
func();
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
1>------ Build started: Project: Working, Configuration: Debug Win32 ------
1>void-type.cpp
1>C:\Users\Thiago Souto\Desktop\VUEPRESS\MASTERS\docs\Resources\C++\Ex_Files_CPlusPlus_EssT\Exercise Files\Chap03\void-type.cpp(7,13): error C2562: 'func': 'void' function returning a value
1>C:\Users\Thiago Souto\Desktop\VUEPRESS\MASTERS\docs\Resources\C++\Ex_Files_CPlusPlus_EssT\Exercise Files\Chap03\void-type.cpp(5): message : see declaration of 'func'
1>Done building project "Working.vcxproj" -- FAILED.
========== Build: 0 succeeded, 1 failed, 0 up-to-date, 0 skipped ==========
2
3
4
5
6
As a parameter type this is one of those places where C and C++ are a little bit different.
By definition and by standard C++ includes the entire C language in its standard, but there are a few little differences here and there.
One of the significant differences is, that in the C language a single void type like this in the parameter list means that the function takes no arguments, because in C you can have a function like this with an empty argument list, but that does that mean that it takes no arguments, you can still pass arguments to that and use them.
In the C language you put a void here to say this function takes no arguments, so in C++ a function declaration with no arguments does mean that the function takes no arguments and your not allowed to pass arguments to it.
// void-type.cpp by Bill Weinman <http://bw.org/>
#include <cstdio>
using namespace std;
void func () {
puts("this is void func ( void )");
}
int main() {
puts("calling func()");
func();
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
So, void in the argument list is simply for compatibility with C. In C++ more often you'll see an empty argument list than you will with the void in there.
So while void is syntactically a type its used only in special circumstances as a return type or as a parameter type, its values to enforce a rule preventing use where value would be expected.
# The auto type
The auto-type is a relatively recent feature in C++, beginning with C++11 and its quickly becoming very common because its just remarkably useful.
Here, I have a code and here you'll notice I have a function that returns a string, and this is an STL string defined here in the string header.
// auto-type.cpp by Bill Weinman <http://bw.org/>
#include <cstdio>
#include <string>
#include <typeinfo>
using namespace std;
string func() {
return string("this is a string");
}
int main() {
auto x = func();
printf("x is %s\n", x.c_str());
if(typeid(x) == typeid(string)) puts("x is string");
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
I declare a variable x with the auto-type and I'm initializing it from the return value of func and so, the compiler at this point knows that the function returns a string and it sees this auto-type, and it simply says, okay x is a string. This is exactly the same as if I had put string there, but instead, I have auto, but I get exactly the same result.
So, this is still a strongly typed variable and it has all the properties of the string.
x is this is a string
x is string
2
And I'm running typeid on x and comparing it with typeid on the string class, and they are the same because that's resolving to true and I'm getting this puts here that says x is string.
Here, we have a vector, which is another STL class, and this is actually a template class and so, its a vector of ints. And we'll get into the details of this later in the course of how vectors work and how they're declared and all, but you can see that that declaration requires a template parameter in the angle brackets and a member of the class a separate iterator class, and so, if you want an iterator, if you want to use a for loop with a vector like this, using the iterator, you need to declare the iterator like this, which is a little bit complex, and a little bit difficult to type and a little bit prone to error.
// auto-type2.cpp by Bill Weinman <http://bw.org/>
#include <cstdio>
#include <vector>
using namespace std;
int main() {
vector<int> vi = { 1, 2, 3, 4, 5 };
for(vector<int>::iterator it = vi.begin(); it != vi.end(); ++it) {
printf("int is %d\n", *it);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
So, instead I can just say auto, and now, when I build and run this, it works perfectly.
// auto-type2.cpp by Bill Weinman <http://bw.org/>
#include <cstdio>
#include <vector>
using namespace std;
int main() {
vector<int> vi = { 1, 2, 3, 4, 5 };
for(auto it = vi.begin(); it != vi.end(); ++it) {
printf("int is %d\n", *it);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
int is 1
int is 2
int is 3
int is 4
int is 5
2
3
4
5
its getting the iterator. its using the iterator in the for loop and I'm even dereferencing the iterator over here. It works exactly the same as if I had done it like this, and I'll build and run and you see we get exactly the same results.
And using auto here is actually even easier to read, its easier to type, and its less prone to error.
So, this feature is a real improvement, but its not without its dangers. Be careful to use auto-types only when the implications are clear and the usage is concise.
Otherwise, you could potentially sacrifice readability and even introduce errors that could be hard to find.
# Unambiguous null pointer constant
In C++, the null constant has always been problematic. lets take a look at why.
// nullptr.cpp by Bill Weinman <http://bw.org/>
#include <cstdio>
using namespace std;
#ifndef NULL
#define NULL (0LL) /* common C++ definition */
#endif
void f( int i ) {
printf("the int is %d\n", i);
}
void f( const char * s ) {
printf("the pointer is %p\n", s);
}
int main() {
f(NULL);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
You'll notice that my screen is displaying an error on line 18. Call to "f" is ambiguous. And why is it ambiguous? Well, you'll notice that I'll have two different function signatures for "f".
On line nine I have one passing an int, and online 13 I have one that passes a constant character pointer. And this is perfectly legal and perfectly common in C++. Of course, it is not legal in C language, and this is where we have this difference.
In C++, we can overload functions by having different functions with the same name and different function signatures. We're getting to the details of that in the chapter later on functions. But for now, just understand that this is completely legal, and under most circumstances, if you call "f" with a constant character pointer, it'll call one of these, and if you call "f" with an integer, it wlil call the other one.
So, to resolve this issue, staring with C++ 11, C++ defines a new key word called null pointer. And I'm just going to come in here and I'm going to say null ptr like that, that resolves the ambiguity.
// nullptr.cpp by Bill Weinman <http://bw.org/>
#include <cstdio>
using namespace std;
#ifndef NULL
#define NULL (0LL) /* common C++ definition */
#endif
void f( int i ) {
printf("the int is %d\n", i);
}
void f( const char * s ) {
printf("the pointer is %p\n", s);
}
int main() {
f(nullptr);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
The specification for C++ says that null pointer is defined as a null pointer constant that can be converted into a null pointer value or null member pointer value.
In other words, this is a special value that says I'm a pointer, I'm a null pointer, and I'm a null pointer of any type.
And so now when I build and run, it says the pointer is zero because it knows there's no more ambiguity. its calling this version with the pointer and not the version with the integer.
the pointer is 00000000
And if instead I give it a zero and build and run, it knows that that's an integer. So the null pointer constant provides a much needed value to be used where the traditional null void pointer value has been used in C but doesn't work in C++. It resolves the ambiguity problem and it can be used in any context of any pointer type.
// nullptr.cpp by Bill Weinman <http://bw.org/>
#include <cstdio>
using namespace std;
#ifndef NULL
#define NULL (0LL) /* common C++ definition */
#endif
void f( int i ) {
printf("the int is %d\n", i);
}
void f( const char * s ) {
printf("the pointer is %p\n", s);
}
int main() {
f(0);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
the int is 0
The specification for C++ says that null pointer is defined as a null pointer constant that can be converted into a null pointer value or null member pointer value.
In other words, this is a special value that says I'm a pointer, I'm a null pointer, and I'm a null pointer of any type. And so now when I build and run, it says the pointer is zero because it knows there's no more ambiguity. its calling this version with the pointer and not the version with the integer.
And if instead I give it a zero and build and run, it knows that that's an integer.
So the null pointer constant provides a much needed value to be used where the traditional null void pointer value has been used in C but doesn't work in C++.
It resolves the ambiguity problem and it can be used in any context of any pointer type.
# 4. Operators
The assignment operator is used to copy a value from one object to another, so if I have int x equals five, I am copying the value five from the literal into the variable x. In this case, I'm also using the assignment operator to initialize a new object, and so, I can do the same with y, int y equals 47, and if I print these out, of course, we get the results we expect. When I build and run, x is five and y is 47.
#include <cstdio>
using namespace std;
int main() {
int x = 5;
int y = 47;
y = x
printf("x is %d\n", x);
printf("y is %d\n", y);
return 0;
}
2
3
4
5
6
7
8
9
10
11
x is 5
y is 47
2
Now, here I've used these assignment operators to initialize a variable. I can also use it assign one variable to another. I can say y equals x and now when I build and run, you notice that both variables are five, have the value five, so in this case, on line nine here, y equals x, you use the assignment operator to copy the value from x into the variable y.
#include <cstdio>
using namespace std;
int main() {
int x = 5;
int y = 47;
y = x
printf("x is %d\n", x);
printf("y is %d\n", y);
return 0;
}
2
3
4
5
6
7
8
9
10
11
x is 5
y is 5
2
We also have arithmetic operators, so I can say x equals y, plus x, and when I build and run here, you notice that x is now equal to 52, the sum of five and 47.
#include <cstdio>
using namespace std;
int main() {
int x = 5;
int y = 47;
x = y + x;
printf("x is %d\n", x);
printf("y is %d\n", y);
return 0;
}
2
3
4
5
6
7
8
9
10
11
x is 52
y is 47
2
its worth noting that these arithmetic operators like plus, and minus, and multiply and divide, so here's y minus x, these arithmetic operators typically return a temporary object, which can then be copied to the assignment operator or used in an expression, and so, I can do the same with multiplication and division.
The modular operator, which is a percent sign, returns the remainder after an integer division.
TIP
Modulus (Remainder) %. x % y The remainder of x divided by y
# Arithmetic assignment operators
| Operator | Symbol | Form | Operation |
|---|---|---|---|
| Assignment | = | x = y | Assign value y to x |
| Addition assignment | += | x += y | Add y to x |
| Subtraction assignment | -= | x -= y | Subtract y from x |
| Multiplication assignment | *= | x *= y | Multiply x by y |
| Division assignment | /= | x /= y | Divide x by y |
| Modulus assignment | %= | x %= y | Put the remainder of x / y in x |
#include <cstdio>
using namespace std;
int main() {
int x = 5;
int y = 47;
x = y % x;
printf("x is %d\n", x);
printf("y is %d\n", y);
return 0;
}
2
3
4
5
6
7
8
9
10
11
x is 2
y is 47
2
And there's also a unary minus. This will return the negative of y, so it'll flip its sign, in this case, it'll become a negative number.
#include <cstdio>
using namespace std;
int main() {
int x = 5;
int y = 47;
x = - y;
printf("x is %d\n", x);
printf("y is %d\n", y);
return 0;
}
2
3
4
5
6
7
8
9
10
11
x is 47
y is -47
2
And there's also, for completeness, a unary plus, which is rarely used, which returns the value with the sign unchanged.
#include <cstdio>
using namespace std;
int main() {
int x = 5;
int y = 47;
x = + y;
printf("x is %d\n", x);
printf("y is %d\n", y);
return 0;
}
2
3
4
5
6
7
8
9
10
11
x is 47
y is 47
2
So, we use these common operators so much that its easy to take them for granted. its a good idea to take a moment and think about how they work.
# Compound assignment operators
C++ supports compound assign operators that allow you to combine an assignment with an arithmetic operation, these are both convenient and efficient.
#include <cstdio>
using namespace std;
int main() {
int x = 5;
int y = 47;
x += y;
printf("x is %d\n", x);
return 0;
}
2
3
4
5
6
7
8
9
10
x is 52
its available for addition, its available for subtraction, multiplication, division, and the modulus, which is the remainder after an integer division.
x -= y;
x /= y;
x *= y;
x %= y;
2
3
4
There's one important distinction between a compound assignment and its equivalent expression, so you could say that x plus equals y is the same as x equals x plus y and certainly the result, at least in this case is the same. The distinction here is that with the separate assignment and addition, x is being evaluated twice, once here and once here. And with the compound assignment, x is being evaluated once and this may not seem significant and certainly in the case of integer arithmetic, its probably not, but when you get into object-oriented applications, where you might be dealing with not necessarily scale or integers, but you might be dealing with more complex objects that double evaluation could have an effect and could make a difference.
x += y;
x = x + y;
2
There's one other distinction here with x equals x plus y, the arithmetic operation which is this expression here actually returns a temporary object, which is then copied into the result. There is no such temporary object in the compound operator, so its just worth understanding how these work. And there are circumstances obviously where these things may make a difference.
The compound assignment operators are convenient, safe, and often more efficient than their common equivalence feel free to use them wherever you would use the equivalent expression, just be aware of the distinctions. Help/Feedback
# Increment and decrement operators
So what's going on here is this increment operator is incrementing the value before it evaluates it.
#include <cstdio>
using namespace std;
int main() {
int i = 0;
printf("x is %d\n", ++i);
printf("x is %d\n", ++i);
printf("x is %d\n", ++i);
return 0;
}
2
3
4
5
6
7
8
9
10
x is 1
x is 2
x is 3
2
3
If I move that to the post-fix version, and we'll go ahead and make three copies of that, when I build and run, you'll notice that it increments after it evaluates the variable.
#include <cstdio>
using namespace std;
int main() {
int i = 0;
printf("x is %d\n", i++);
printf("x is %d\n", i++);
printf("x is %d\n", i++);
return 0;
}
2
3
4
5
6
7
8
9
10
x is 0
x is 1
x is 2
2
3
And of course, there's both increment and decrement versions.
The increment and decrement operators also work with pointers, and they work in a special way with pointers.
We have an array of five values and we declare a pointer to the array. And we print while incrementing. And each of these is a post-fix increment to start with. So when I build and run this, you notice that it prints the address and the value.
// pointer-incr.cpp by Bill Weinman <http://bw.org/>
#include <cstdio>
using namespace std;
void printp(char *p) {
printf("pointer is %p, value is %d\n", p, *p);
}
int main()
{
char arr[5] = { 1, 2, 3, 4, 5 };
char *p = arr;
printp(p++);
printp(p++);
printp(p++);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
pointer is 010FFC6C, value is 1
pointer is 010FFC6D, value is 2
pointer is 010FFC6E, value is 3
2
3
You notice the address increases by one. And the value increases by one. The address increases by one because we're dealing with characters here, which are eight bits, which take up one byte of memory.
Because a pointer knows its size, if I change this from character and instead put in an int, and I'll do that in all three places here and build and run, you'll notice that now, its incrementing by four in the address, rather than by one because an integer takes up four bytes on this system, a 32-bit integer. And you'll notice the same thing, that if we move our increments to pre-fix rather than post-fix, it increments before it calls the function, before it evaluates the pointer.
// pointer-incr.cpp by Bill Weinman <http://bw.org/>
#include <cstdio>
using namespace std;
void printp(int *p) {
printf("pointer is %p, value is %d\n", p, *p);
}
int main()
{
int arr[5] = { 1, 2, 3, 4, 5 };
int *p = arr;
printp(p++);
printp(p++);
printp(p++);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
pointer is 004FF99C, value is 1
pointer is 004FF9A0, value is 2
pointer is 004FF9A4, value is 3
2
3
its worth understanding that the pre-fix version of the increment and decrement operators is slightly more efficient than the post-fix version, and that's because the post-fix version, the post-increment, requires making a copy of the value before its returned from the object.
Keep in mind that the pre-fix version increments before returning the value and the post-fix version increments after evaluating the value.
# Relational (comparison) operators
The comparison operators are used to compare for equality or for relative value.
Operators Description
> Greater than
>= Greater than or equal to
== Is equal to
!= Is not equal to
<= Less than or equal to
< Less than
2
3
4
5
6
7
8
9
10
11
# Logical operators
The logical operators are used for testing logical conditions.
- ! Logical NOT
- && Logical AND
- || Logical inclusive OR
# Bitwise operators
The bitwise Boolean arithmetic operators allow you to perform binary operations on integer values.
#include <stdio.h>
int main()
{
// a = 5(00000101), b = 9(00001001)
unsigned char a = 5, b = 9;
// The result is 00000001
printf("a = %d, b = %d\n", a, b);
printf("a&b = %d\n", a & b);
// The result is 00001101
printf("a|b = %d\n", a | b);
// The result is 00001100
printf("a^b = %d\n", a ^ b);
// The result is 11111010
printf("~a = %d\n", a = ~a);
// The result is 00010010
printf("b<<1 = %d\n", b << 1);
// The result is 00000100
printf("b>>1 = %d\n", b >> 1);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
a = 5, b = 9
a&b = 1
a|b = 13
a^b = 12
~a = 250
b<<1 = 18
b>>1 = 4
2
3
4
5
6
7
Here I have a working copy of bprint.cpp from chapter four of the exercise files. The purpose of this exercise file is simply to provide a quick and portable way to display binary values. Standard printf doesn't provide one so I wrote this simple u8 to c-string function which you can see here starting on line eight. To convert an eight bit byte to a string representation of binary bits and if you look down here in main, you see where I call it and if I build and run you'll see the result is I'm displaying x in binary and y in binary and the result of this expression in binary.
// bprint.cpp by Bill Weinman <http://bw.org/>
// updated 2018-10-27
#include <cstdio>
#include <cstdint>
using namespace std;
// unsigned 8-bit to string
const char * u8_to_cstr(const uint8_t & x) {
static char buf[sizeof(x) * 8 + 1];
for(char & c : buf) c = 0; // reset buffer
char * bp = buf;
for(uint8_t bitmask = 0b10000000; bitmask; bitmask >>= 1) {
*(bp++) = x & bitmask ? '1' : '0';
}
return buf;
}
int main()
{
uint8_t x = 5;
uint8_t y = 10;
uint8_t z = x | y;
printf("x is %s\n", u8_to_cstr(x));
printf("y is %s\n", u8_to_cstr(y));
printf("result is %s\n", u8_to_cstr(z));
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
x is 00000101
y is 00001010
result is 00001111
2
3
So this expression has x or y and that's a binary or, a bitwise or, and so you'll notice in the results that each of the bits in the result is the or of the corresponding bits in x and y.
Symbol Operator:
&= bitwise AND assignment
|= bitwise inclusive OR assignment
^= bitwise exclusive OR assignment
<<= left shift assignment
>>= right shift assignment
2
3
4
5
6
7
8
9
# Ternary conditional operator
The ternary conditional operator is a simple shortcut for choosing a value based on a condition.
We'll have int x = 5, and int y = 42, and then a const char pointer s equals if x is greater than y, question mark, "yes", colon, "no".
#include <cstdio>
using namespace std;
int main()
{
int x = 5;
int y = 42;
const char * s = x > y ? "yes" : "no";
puts(s);
return 0;
}
2
3
4
5
6
7
8
9
10
11
no
# Dynamic memory operators
The new and delete operators are used to allocate and free memory in C++. These operators are specific to C++ and are not available in C.
So this is actually really simple. You have new, and you tell it what and how many and you have delete and you give it the square brackets if how many is more than one.
#include <cstdio>
#include <new>
using namespace std;
constexpr size_t count = 1024;
int main() {
printf("allocate space for %lu long int at *ip with new\n", count);
// allocate array
long int * ip;
try {
ip = new long int [count];
} catch (std::bad_alloc & ba) {
fprintf(stderr, "Cannot allocate memory (%s)\n", ba.what());
return 1;
}
// initialize array
for( long int i = 0; i < count; ++i ) {
ip[i] = i;
}
// print array
for( long int i = 0; i < count; ++i ) {
printf("%ld ", ip[i]);
}
puts("");
// deallocate array
delete [] ip;
puts("space at *ip deleted");
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
$ ./working
allocate space for 1024 long int at *ip with new
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58
...
993 994 995 996 997 998 999 1000 1001 1002 1003 1004 1005 1006 1007 1008 1009 1010 1011 1012 1013 1014 1015 1016 1017 1018 1019 1020 1021 1022 1023
space at *ip deleted
2
3
4
5
6
7
8
We have allocate space for 1,024 long int and it prints out the array starting at zero and ending 1,023 so we know that we've successfully allocated the space, we've populated the space and we've deleted the space with the delete and all of that worked just fine.
Now I want to talk a little bit about this try catch block and in order to do that I'm going to demonstrate by allocating more space than I can and this may or may not work on your system, you can try it, on my system I have to allocate a whole mess of these in order for it to not work, so I'm going to put 12 zeroes after this 1,024, one two three, one two three, one two three, one two three that should be 12 and I'm going to save and build and run and you'll notice that I get all kinds of stuff down here we have error messages from something called malloc and if you're familiar with the C language you'll know what malloc is. Malloc and free are the C ways to allocate and deallocate memory and new and delete basically call malloc and free but new and delete is the C++ way to do it and the syntax is much easier and much simpler and then you'll notice down here, it says cannot allocate memory and standard bad alloc and if we see here this error message cannot allocate memory with the parenthesis and %s and we're passing that the result of a function call to what in the ba object and we've declared a ba object here in the catch clause of the try and catch.
So basically the way that exceptions work in C++ is that you've got this try block and inside the try block is what you're trying and if that's interrupted with an exception than the catch block catches the exception and in this case we're passing it this object of type bad alloc and its a reference to the object and then we can use ba.what to catch that error message and print it and exit with an error code of one, and so that's just an overview.
ip = new(nothrow) long int [count];
if(ip == nullptr) {
fprintf(stderr, "Cannot allocate memory\n");
return 1;
}
2
3
4
5
now you can use new without exceptions and here's how you do this. its not recommended but if for some reason you don't want to use the try catch block you can do this instead. Ip that's our pointer equals new and you pass it this nothrow value, and that's a special constant that tells new not to throw an exception, and then the rest of it is the same, long int and the count and a semicolon, and now its not going to throw an exception the error still happens and we have to catch the error. So here's how we catch the error, we say if ip is equal to the null pointer value, the special null pointer which we talked about earlier, and we can say fprintf and send that to standard error like we do in the catch below and we can say, cannot allocate memory. We don't get to give it the error message inside the parenthesis because we don't have that and so we give it a new line, and there and then return one and now I can build and run and I'm still catching the error you notice here it says cannot allocate memory. I'm not getting the error message from the exception but I'm still catching the error so that our program doesn't completely crash.
TIP
Now all that said, the recommended way to do this is with the try and catch block, and so its best that you do it that way and that way you're catching the exceptions and you're doing it the recommended way. The new operator is used for allocating space for objects in C++ every object allocated with new must be destroyed with delete otherwise your program will leak memory.
# Type cast
The typecast operator converts a value from one type to another compatible type.
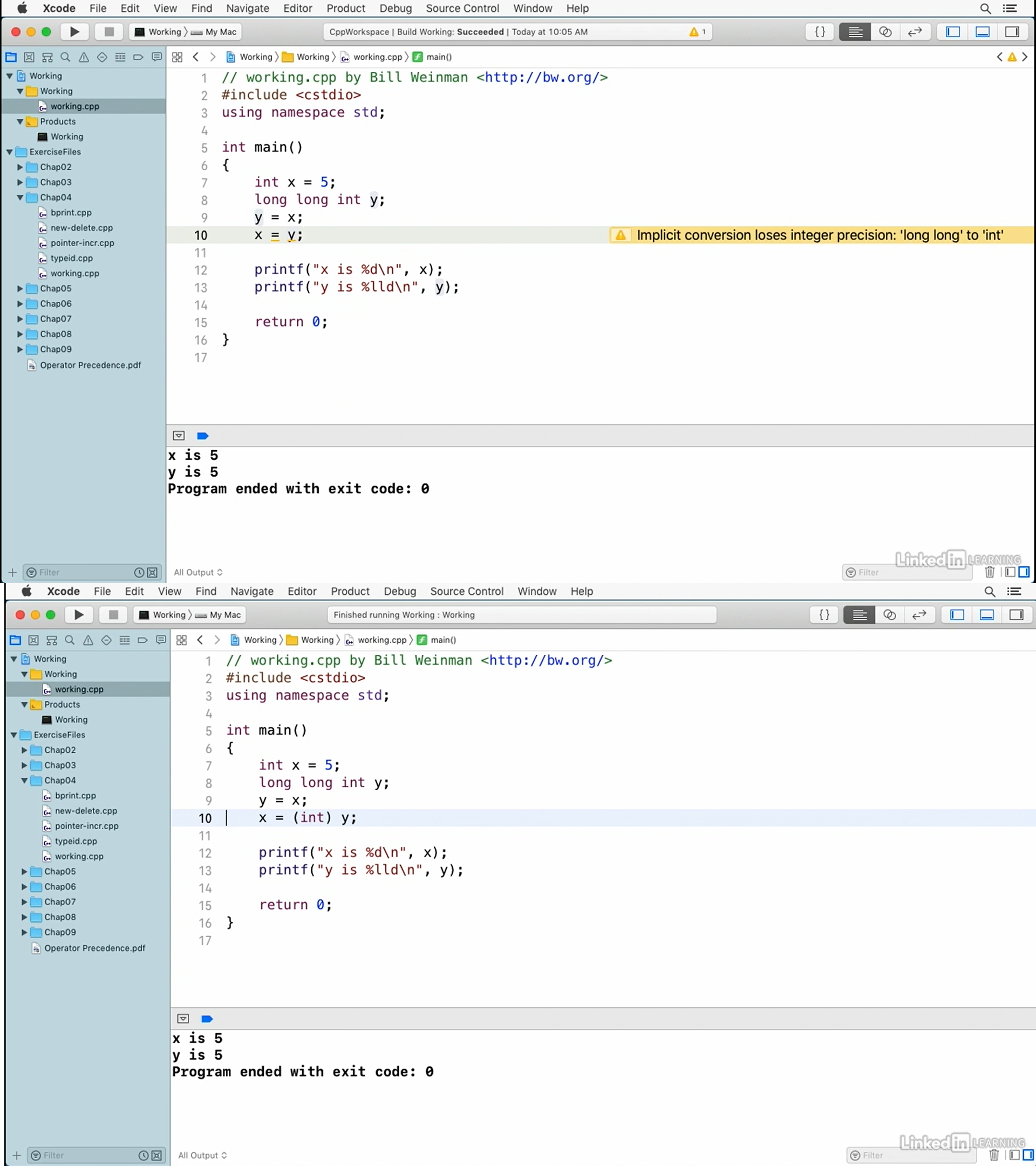
# Using sizeof
The size of operator is used to determine the size of an object.
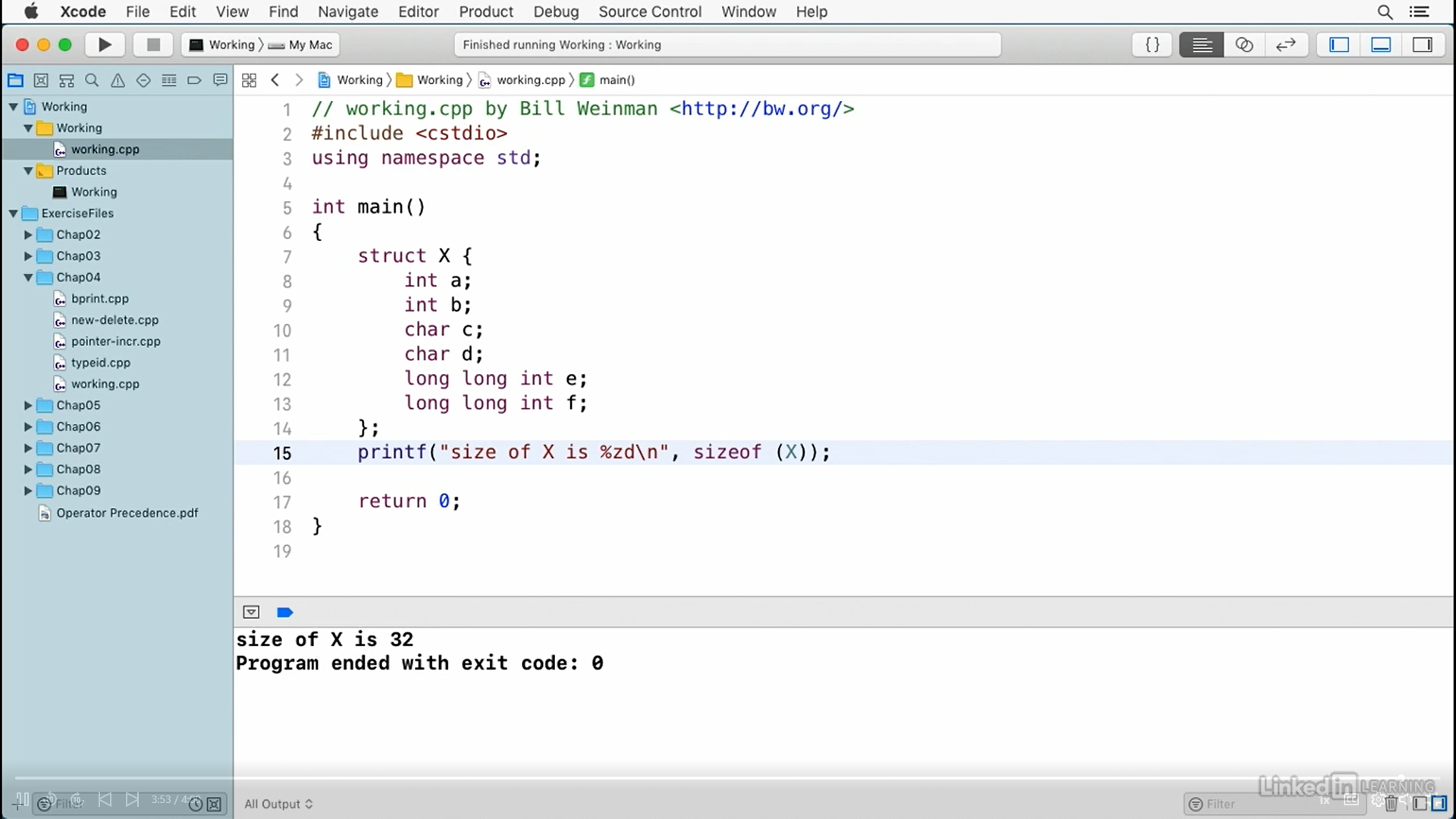
# Using typeid
The typeid operator is used to determine the type of an object. It returns a typeinfo object which is defined in the typeinfo header
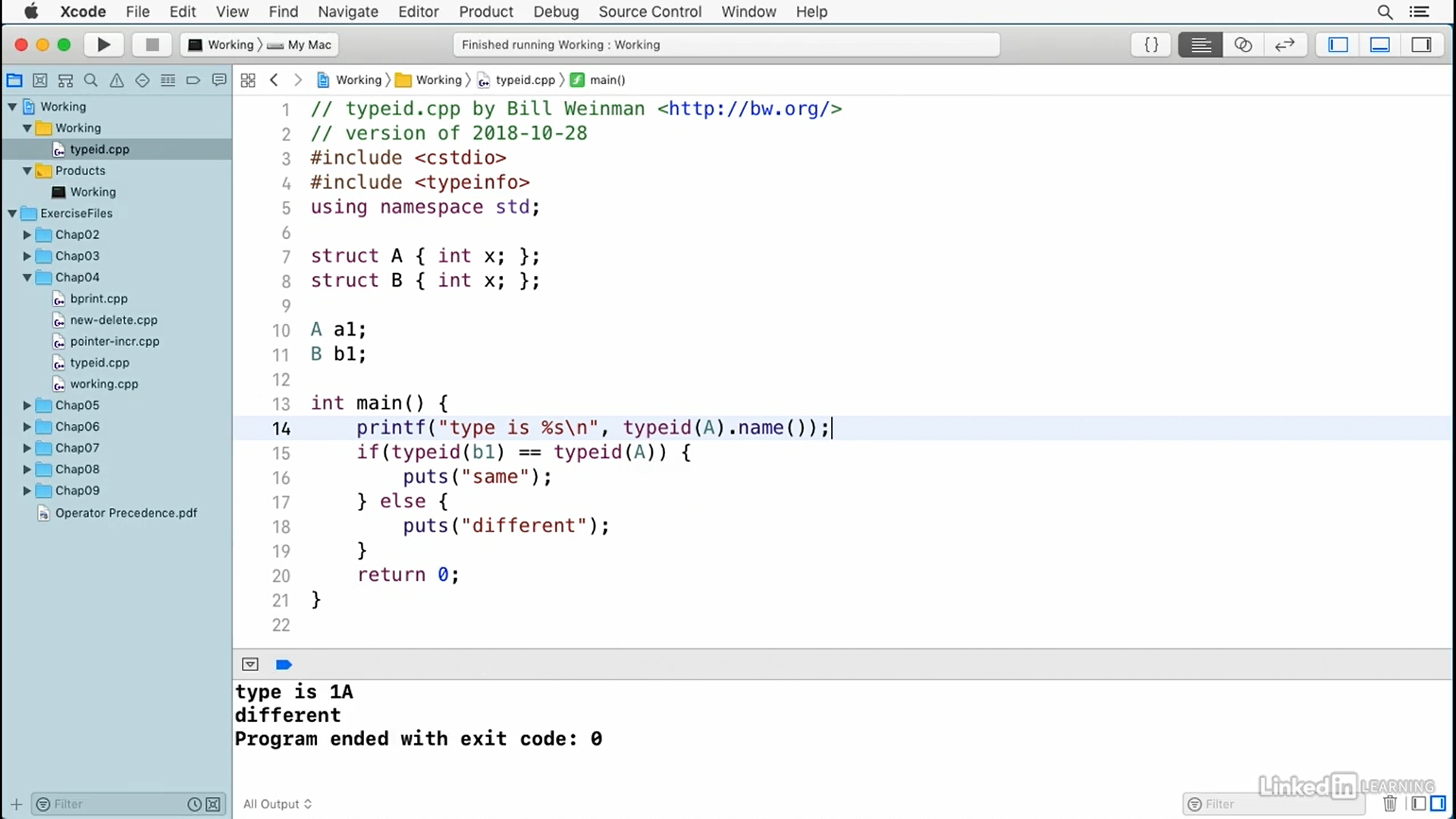
The typeid operator may be used to determine the type of an object. While you can retrieve a string representation of the type, its often easier to simply compare the results of typeid to determine the type of an object.
# Operator precedence
Operator precedence is the order in which operators are evaluated in an expression. This expression could have different results depending upon the order in which its evaluated.
The order of evaluation without any parenthesis is that the division happens first and then the multiplication and then the addition.
Operators near the top of the table are evaluated first and associativity is the order in which operators are evaluated. Most operators are evaluated left to right except prefix unary and assignment operators are evaluated right to left.
# 5. Functions
#include <cstdio>
using namespace std;
void func()
{
puts("this is func()");
}
int main()
{
puts("this is main()");
func();
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
Because the function has to be declared before use we can declare the signature of the function and then make the function in a forward declaration.
#include <cstdio>
using namespace std;
void func();
int main()
{
puts("this is main()");
func();
return 0;
}
void func()
{
puts("this is func()");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
In fact, its common sometimes to put these function declarations in a header file. So I'm going to take this func.h and I'm going to make a copy of it up here. You'll notice when we look at it, it has nothing in it but this function declaration. So I can come in here and I can say #include "func.h" and when I build and run, now everything works as if I had declared the function in the same space in this file, as we had before, before main.
func.h
#ifndef FUNC_H_
#define FUNC_H_
void func();
#endif // FUNC_H_
2
3
4
5
6
Now we can use like this:
#include <cstdio>
#include "func.h"
using namespace std;
int main()
{
puts("this is main()");
func();
return 0;
}
void func()
{
puts("this is func()");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# Passing values to a function
Parameters are passed to a function by declaring them inside parentheses of the function definition, and passing them in the parentheses of the function call.
#include <cstdio>
using namespace std;
void func(int i)
{
printf("the value is %d\n", i);
}
int main()
{
printf("this is main()\n");
func(42);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
this is main()
the value is 42
2
WARNING
Explore this class in more details later, for details of call from reference
So when you pass something larger than a simple value, you'll usually want to use a reference or a pointer. So as a more practical example, lets include the string header here and use an stl string, and remove all this and say, string s = "this is a string!" And how about that? And we'll call func with the s like this, and we have to redeclare our function now. Our function is now const string & s. So its taking a reference to the string, but you notice that its const, so it can't change it and it can't create side effects. And we'll just say down here, the value is %s. So that takes a C string, so we'll take s.c_str like that, and now when I build and run, you see it says the value is "this is a string!" So we've passed the string as a reference, we've done so safely with the const qualifier here, and that's very important. And we passed something relatively large. Obviously, this is not a very big string. All we're passing on the stack is the reference. And remember, internally, a reference is managed as a pointer, and so its a relatively small amount of data that gets passed on the stack.
#include <cstdio>
#include <string>
using namespace std;
void func(const string & s)
{
printf("the value is %s\n", s.c_str());
}
int main()
{
string s = "this is a string!";
func(s);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
the value is this is a string!
By default, function parameters are passed by value in C++. You can pass pointers or references if you need to pass larger values, but you'll need to do so explicitly.
# Using automatic and static variables
Variables declared in a function default to automatic storage. Other storage options are available.
Automatic storage is stored on the stack which is temporary and the value is not carried from one invocation to another.
#include <cstdio>
using namespace std;
void func()
{
int i = 5;
printf("i is %d\n", ++i);
}
int main()
{
puts("this is main()");
func();
func();
func();
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
this is main()
i is 6
i is 6
i is 6
2
3
4
If I use the storage class modifier static to change that storage to static from automatic, now the variable hangs around between invocations, so when I build and run, you'll notice that each time we run this, each time we call a function, I is incremented, so its like a counter.
#include <cstdio>
using namespace std;
void func()
{
static int i = 5;
printf("i is %d\n", ++i);
}
int main()
{
puts("this is main()");
func();
func();
func();
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
this is main()
i is 6
i is 7
i is 8
2
3
4
TIP
Variables declared in a function default to automatic storage, if you want your data to be persistent, you may declare your variables as static.
# Returning values from a function
A function may return a value back to its caller with a return statement.
#include <cstdio>
using namespace std;
int func(int i)
{
puts("This is func()");
return i * 2;
}
int main()
{
puts("this is main()");
int x = func(42);
printf("x is %d\n", x);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
this is main()
This is func()
x is 84
2
3
You'll notice that my result says x is 84, as expected. So now func returns an int value, just like passing a value to a function, return values are copied to the stack and returned on the stack.
This means that you cannot return anything large. If you need to return a large object, you can do so with a reference.
I'm going to say const static s or string s equals and then I'm going to simply return s and that'll return the referenced s because I have this ampersand here in the return type, so its returning a reference.
And now, I'm going to say const string s equals func and print f func returns percent s and s.c_str to give us a c string for our s value.
#include <cstdio>
#include <string>
using namespace std;
const string & func()
{
const static string s = "this is func()";
return s;
}
int main()
{
puts("this is main()");
const string s = func();
printf("func() returns %s\n", s.c_str());
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Now when I build and run, we get func returns. This is func, which is exactly what we expected.
this is main()
func() returns this is func()
2
So a couple of notes here. You'll notice that our storage here is const static and, of course, static is because automatic variables are stored on the stack and we don't want to store a big object on the stack. And while, obviously, this is not a huge object, its probably enough that we don't really want to store it on the stack. And const because const is just always a good idea, especially with static storage, especially when you're passing around references to that static storage. But its generally a good idea for anything that you're not going to need to change in the future.
I tend to default to using const more often than not, and then if I find that I need to actually change something, I can always remove it. And, of course, we're returning a const reference to the string and we're taking our variable that's getting initialized by the return value for func, that is also a const string and this is being initialized, of course, by that reference. And so, that'll be copied into this new variable.
If I wanted to, I could use an ampersand there and now, we're not even using a temporary variable here and we're actually only using this const static storage that's passed out from the function.
#include <cstdio>
#include <string>
using namespace std;
const string& func()
{
const static string s = "this is func()";
return s;
}
int main()
{
puts("this is main()");
const string & s = func();
printf("func() returns %s\n", s.c_str());
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Off course, we get the same result:
this is main()
func() returns this is func()
2
Returning a value from a function is much like passing values to a function and that happens on the stack. And you'll want to keep all of those caveats in mind as you do so.
# Using function pointers
In C++, you may take the address of a function and assign it to a pointer. This is called a function pointer. Function pointers can be very convenient in some circumstances.
And we have our function up here, we're just going to leave that alone and I'm going to come down here and I'm going to create a function pointer. So our function signature has void as its return type. So I'm simply going to say void and then, in parentheses, pfunc, that'll be the name of our pointer. And the parentheses after it equals and func, like that.
Now we have a pointer named pfunc, which points to our function, so down here, where it says func, I can simply make it say pfunc and build and run and it calls our function, simply by dereferencing the pointer.
#include <cstdio>
using namespace std;
void func()
{
puts("this is func()");
}
int main()
{
void (*pfunc)() = func;
puts("This is main()");
pfunc();
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
This is main()
this is func()
2
Now, pfunc, like that, as a function call, that's really a shortcut that's available in C++. In C, you need to do this with parentheses and a dereference operator like that. And of course, that works exactly the same in C++. But either of those syntaxes is acceptable in C++. So that's what a function pointer looks like.
# Practical case for using function pointers
So this is what's called a simple jump table and I'll often use this for menu-based or choice-based applications where I have either somebody typing a menu option or somebody selecting a menu option with a mouse or something and I want to be able to jump easily to different points of execution, different functions within the code.
#include <cstdio>
using namespace std;
const char * prompt();
int jump( const char * );
void fa() { puts("this is fa()"); }
void fb() { puts("this is fb()"); }
void fc() { puts("this is fc()"); }
void fd() { puts("this is fd()"); }
void fe() { puts("this is fe()"); }
void (*funcs[])() = { fa, fb, fc, fd, fe };
int main() {
while(jump(prompt())) ;
puts("\nDone.");
return 0;
}
const char * prompt() {
puts("Choose an option:");
puts("1. Function fa()");
puts("2. Function fb()");
puts("3. Function fc()");
puts("4. Function fd()");
puts("5. Function fe()");
puts("Q. Quit.");
printf(">> ");
fflush(stdout); // flush after prompt
const int buffsz = 16; // constant for buffer size
static char response[buffsz]; // static storage for response buffer
fgets(response, buffsz, stdin); // get response from console
return response;
}
int jump( const char * rs ) {
char code = rs[0];
if(code == 'q' || code == 'Q') return 0;
// get the length of the funcs array
int func_length = sizeof(funcs) / sizeof(funcs[0]);
int i = (int) code - '0'; // convert ASCII numeral to int
if( i < 1 || i > func_length ) {
puts("invalid choice");
return 1;
} else {
funcs[i - 1](); // array is zero-based
return 1;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
Choose an option:
1. Function fa()
2. Function fb()
3. Function fc()
4. Function fd()
5. Function fe()
Q. Quit.
>> 2
this is fb()
Choose an option:
1. Function fa()
2. Function fb()
3. Function fc()
4. Function fd()
5. Function fe()
Q. Quit.
>> 1
this is fa()
Choose an option:
1. Function fa()
2. Function fb()
3. Function fc()
4. Function fd()
5. Function fe()
Q. Quit.
>> q
Done.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
And so lets take a look at how this works. Here I have four declarations and we're going to look at those functions in a little bit. One of them is for prompting the user and returning a character string. And the other is for the jump table code itself. Here we have five very simplistic actual functions. Function fa which prints this is fa, function fb, et cetera, through fe. And here we have an array of function pointers. And so you notice our function pointer syntax but this time it has the square brackets to say this is an array and that array is initialized with this initializer list with the addresses of each of the five functions, these simple functions that we just declared on lines 11 through 15.
Now our main is very, very simple. It simply calls prompt and passes that return value to jump and then says done. And it calls those in a while loop until jump returns false. And so our prompt function looks like this. It simply puts out a bunch of strings saying choose an option, its a little menu there. And then it sets up a little buffer and calls fgets to get the response from the console and it returns the response buffer. Very, very simple. Now here's our actual jump table code.
And I've been known to say that programming is very much about setting up your data properly and once you do that, the code becomes simple. And this is a nice example of that.
Jump returns either one or zero, returns zero when its done and it returns one to continue because you remember how its called here in this while loop, this very simple while loop that doesn't actually even have a block of code. its just call jump over and over again until its done. So we get our return string from the prompt, our response string from the prompt, and we check to see if the first character is a q for quit and if it is, we return zero from jump and that will end the program. If its not, then we're going to check it for its range.
We have to figure out what the range is, so we look at the size of the array and we find that there's five items in the array. Then we take our response and we convert it to an int from ASCII numeral.
The simple way to do that is to subtract zero, the ASCII code zero, from that integer and then you get an integer that is the number of the digit that was typed. If its less than one or if its greater than our function length, then we put invalid choice. Otherwise, here we go, we call the function from the array. its as simple as that.
Remember that our array is zero-based, so option number one is going to be zero. So I take our little integer there and I subtract one from it and use that to index into the array and return one and we're done.
TIP
We have our functions, we have our function array, which is an array of pointers to those functions and we select from that array and call the function. its a lot more simple than it looks.
So function pointers can be useful. You're not going to need them often but when you do, they're extremely convenient.
WARNING
Practice this example with variable functions later on
# Overloading function names
In C++, its possible to have different functions with the same name. The compiler selects which function to called based on the entire function signature, not just the function name. This behavior is different than in C, where each function must have a unique name.
In C++, the function signature consists of the return type, the function name, and the list of argument types.
#include <cstdio>
using namespace std;
// volume of a cube
double volume( double a ) {
printf("cube of %.3lf\n", a);
return a * a * a;
}
// volume of a cylinder
double volume( double r, double h ) {
const static double _pi = 3.141592653589793;
printf("cylinder of %.3lf x %.3lf\n", r, h);
return _pi * r * r * h;
}
// volume of a cuboid
double volume( double a, double b, double c ) {
printf("cuboid of %.3lf x %.3lf x %.3lf\n", a, b, c);
return a * b * c;
}
int main() {
printf("volume of a 2 x 2 x 2 cube: %.3lf\n", volume(2.0));
printf("volume of a cylinder, radius 2, height 2: %.3lf\n", volume(2.0, 2.0));
printf("volume of a 2 x 3 x 4 cuboid: %.3lf\n", volume(2.0, 3.0, 4.0));
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
cube of 2.000
volume of a 2 x 2 x 2 cube: 8.000
cylinder of 2.000 x 2.000
volume of a cylinder, radius 2, height 2: 25.133
cuboid of 2.000 x 3.000 x 4.000
volume of a 2 x 3 x 4 cuboid: 24.000
2
3
4
5
6
There are some rules to this.
- The return type cannot be the only distinguishing factor, but the constness of the return type can be, and often is.
- And there are rules about how types are promoted to distinguish parameters, so its a good idea to test your overload of functions thoroughly.
This is one area where C++ differs from C significantly. In C, a function is distinguished only by its name, and this example would not compile.
So in C++, functions are distinguished by their signatures, so its possible to have multiple functions with the same name, that operate with different parameters, and with different return types, and this is called function overloading.
# Defining a variable number of arguments
For those times when you need a function that may take a varying number of arguments C++ provides variadic functions.
TIP
You'll notice right away this header on line four that we're including C Standard Argument, cstdarg And this has macros and definitions and types that are used for the variadic functions.
So inside the function we define a va_list. And this is a typedef that's found in C Standard Argument that defines the variable that will be used for the variadic arguments. And down here there's a macro called va_start which takes two arguments.
We call va_arg which is another macro and it takes its arguments, the argument pointer and the type of the next argument. And what this does is it takes that argument and then it increments the pointer to the argument after that one.
So whatever the type is, that'll be used to define how far that pointer is incremented. And then it returns that actual argument. In this case, of this average, all of our arguments are going to be doubles.
And then we have the macro va_end. And again this is in C Standard Arguments and every time you have a va_start you must have a va_end. va_end releases memory and it does things to clean up properly so that your program doesn't crash and leak memory. va_end is required. Every call to va_start must be matched by a call to va_end.
#include <cstdio>
#include <cstdarg>
// first argument is int count of remaining args
// ... remaining args are doubles for average
double average(const int count, ...)
{
va_list ap;
int i;
double total = 0.0;
va_start(ap, count);
for(i = 0; i < count; ++i) {
total += va_arg(ap, double);
}
va_end(ap);
return total / count;
}
// works like printf, format plus args
int message(const char * fmt, ...) {
va_list ap;
va_start(ap, fmt);
int rc = vfprintf(stdout, fmt, ap);
puts("");
va_end(ap);
return rc;
}
int main() {
message("This is a message");
message("Average: %lf", average(5, 25.0, 35.7, 50.1, 127.6, 75.0));
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
This is a message
Average: 62.680000
2
And you see, we have our average. We're calling it with five arguments, 25, 35.7, 50.1, 127.6 and 75.0. And then we're taking the average of those which is 62.68. So the first argument is the count and then one, two, three, four, five arguments, for the number of things that will be averaged.
You know this is being called with something called message and message looks like its working very much like printf works. And that's because, this is our second example of variadic arguments. The first example showed how to process the arguments individually. This one shows how to pass off those arguments to another function that uses them. In this case the function is this vfprintf. its like fprintf but instead of taking arguments directly it takes an argument pointer, a va_list.
# Using recursion
In mathematics, a recursive function is a function that refers to itself. In fact, if you search Google for the word, recursion, you'll get a note that says, did you mean recursion? For example, if factorial is defined as the product of all positive integers less than or equal to its prime factor, in other words, the factorial of five is equal to 5x4x3x2x1, which interestingly is equal to the factorial of five times the factorial of four.
5! = 5 x 4 x 3 x 2 x 1
5! = 5 x 4!
n! = n x n-1 x n-2 ... x 1
n! = n x (n-1)!
This is an example of recursion in mathematics. lets try this in C++.
#include <cstdio>
using namespace std;
unsigned long int factorial( unsigned long int n ) {
if( n < 2 ) return 1;
return factorial( n - 1 ) * n;
}
int main() {
unsigned long int n = 5;
printf("Factorial of %ld is %ld\n", n, factorial(n));
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
Factorial of 5 is 120
Now, its worth noting that for every recursive function call, memory is allocated for the parameters, for any local variables, for the return value, and for other function call overhead all on the stack, and the stack is a limited resource. So, a loop is often the preferred and often, the more efficient solution.
WARNING
Exercise:
I will leave it as an assignment for you to create a factorial function that uses a loop instead of recursion.
# 6. Classes and Objects
# Overview of classes and objects
In C++ Classes are like custom data types. They're designed to be used like the fundamental types provided by the C++ language. In C++ Classes and Objects are extremely powerful with many features and capabilities. This chapter will cover the basics, which should be enough for many purposes.
WARNING
Come back to the Overview lesson for the definitions
# Defining a class
Classes in C++ are powerful and flexible this is the fundamental unit of object oriented programming.
This is an example of a very simple class, you see the comment, very simple class.
its defined with the class keyword and then the name of the class. In this case the class is called C1.
And then this is the private section, we could have a private keyword here, to define the private section but it actually de futz to private in a class. And we have an integer, its called i, and it has an initial value of zero.
And then a public section, and in the public section we have a setter, to set the value, so this is a complete function, and its called a function member, or member function. Sometimes its called a method, but in this case its simply a function and its called set value. And it takes an integer value as its argument and, in the body of the function it copies that value into the variable i, which is the data member i, up there.
And then we have another function that returns an int. And it simply has one statement, to return the value from our data member. Very simple class.
And so we initialize an integer, and then we initialize an object from our class. So the type is C1, our class, and the variable is our object o1. And we can call set value by saying o1.setvalue like this, and we give it the value 47, and then we say o1.getvalue to retrieve the integer.
#include <cstdio>
using namespace std;
// a very simple class
class C1 {
int i = 0;
public:
void setvalue( int value ) { i = value; }
int getvalue() { return i; }
};
int main() {
int i = 47;
C1 o1;
o1.setvalue(i);
printf("value is %d\n", o1.getvalue());
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
When I build and run, it says the value is 47.
value is 47
Normally its considered best practice to separate the interface and the implementation, and we won't always do this in our examples, just to keep them simple. Especially if they're one liners like this, One liners like this I will often include in the interface.
But for example we can take these, and we can have them as separate functions, and you'll often see it this way.
So you have the definition, in the class definition, which we can call the interface. And then the implementation separately , often even in a separate file. So there you have it, like a normal function, and in order to make it part of the class, you have to say C1, the name of the class, like that, and that makes it part of the class. You see that undeclared identifier goes away there.
So we can do the same thing here, C1, two columns, that tells it that its part of the class.
#include <cstdio>
using namespace std;
// a very simple class
class C1 {
int i = 0;
public:
void setvalue(int value);
int getvalue();
};
void C1::setvalue(int value) {
i = value;
}
int C1::getvalue() {
return i;
}
int main() {
int i = 47;
C1 o1;
o1.setvalue(i);
printf("value is %d\n", o1.getvalue());
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
When I build and run, we get the same result.
value is 47
So now these, function members are a separate implementation and they're often in a separate file.
So once your code gets to be more than a few lines, its actually a lot more convenient, to work with these in separate files, and I'll show you examples later in this chapter. But for teaching purposes, and as you're learning the basic syntax of C++ classes, its often more convenient to show it all in one file like this.
# Data members
C++ classes are based upon C structures. In fact, you can create a class using either the struct or the class keyword. Here I have a working copy of working.cpp from chapter six of the exercise files.
And if I come down here I can create a structure using the struct keyword. I'll call it capital A, and I'll give it three data members, int ia, int ib, and int ic. And then we'll come down here into main and we'll create an object based on this structure. The structure is capital A, and we'll call our object lowercase a, and we'll initialize it with an initializer list, one, two, three. And we'll print it with a printf, like this. And we can use the member operator like a.ia, and a.ib, and a.ic, like that. And when I build and run you'll notice that we get a result.
#include <cstdio>
using namespace std;
struct A {
int ia;
int ib;
int ic;
};
int main() {
A a = { 1, 2, 3 };
printf("ia is %d, ib is %d, ic is %d\n", a.ia, a.ib, a.ic);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
ia is 1, ib is 2, ic is 3
Now here's what's interesting, this structure, its really just a class with three public data members. So if I change this to class, you'll notice that it doesn't build anymore because it says there's no matching instructor. What its really trying to say is that those data members are no longer public, they are now private, because class defaults to private members and struct defaults to public members. And that's really the only difference between them.
#include <cstdio>
using namespace std;
class A {
public:
int ia;
int ib;
int ic;
};
int main() {
A a = { 1, 2, 3 };
printf("ia is %d, ib is %d, ic is %d\n", a.ia, a.ib, a.ic);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
But typically in a class, an object oriented interface, you want to keep your data members private, and you want to access them through public function methods, called accessors.
You'll notice we have a class and it has three private members, two integers and a string. So I've included our string header here as well. And we have setters, function members for setting each of these members, and we have function members for getting the values for each of these function members. And you'll notice that I'm initializing it not with an initializer list, but with a constructor. And this is the constructor here, we'll talk about constructors later in this chapter, but its basically a member function with the same name as the class itself, and its used to initialize each of the data members. This is a very simple constructor here. And so when I build and run, you'll notice I'm getting the results from each of these getters, a.get the function, with the function call operator, and getb_cstr, its a C-string version of the getb that uses the C-string function member from the string class to give us a C-string and getting the value of c with getc. geta and getc, they simply return the value of the data members like that. So its all relatively simple. Again we're going to get into the details of most of this later on in this
#include <cstdio>
#include <string>
using namespace std;
class A {
int ia = 0;
string sb = "";
int ic = 0;
public:
A ( const int a, const string & b, const int ic ) : ia(a), sb(b), ic(3) {};
void seta ( const int a ) { ia = a; }
void setb ( const string & b ) { sb = b; }
void setc ( const int c ) { ic = c; }
int geta () const { return ia; }
const string & getb () const { return sb; }
const char * getb_cstr () const { return sb.c_str(); }
int getc () const { return ic; }
};
int main() {
A a(1, "two", 3);
printf("ia is %d, sb is %s, ic is %d\n", a.geta(), a.getb_cstr(), a.getc());
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
ia is 1, sb is two, ic is 3
C structures and classes are actually identical except that structure members default public while class members default private. its good practice to use struct when the structure will only have data members, and to use class when there's also function members and you want more of an encapsulated interface.
# Function members
C++ classes can have member functions that act as methods for the class.
This is a very simple class. It has a data member, which is an integer, i, and a couple of function members for setting and getting the value. The data member is private by default. This is by design because its considered best practice to encapsulate object data and to use object functions to access that object data. So we have those functions for setting and getting the value.
Now we declare an object of type C1 called o1, and we use setvalue to set the value of the data member and getvalue to get the value of the data member
#include <cstdio>
using namespace std;
class C1 {
int i = 0;
public:
void setvalue(int value) { i = value; }
int getvalue() { return i; }
};
int main() {
int i = 47;
C1 o1;
o1.setvalue(i);
printf("value is %d\n", o1.getvalue());
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
value is 47
Now, its also considered best practice to separate the interface from the implementation. So the class definition here is considered the interface. And when they're just one line like this, I'll often include the code for a function member in the interface, just because its convenient. But its usually considered best practice to put them separately.
#include <cstdio>
using namespace std;
class C1 {
int i = 0;
public:
void setvalue(int value);
int getvalue();
};
void C1::setvalue ( int value ) {
i = value;
}
int C1::getvalue() {
return i;
}
int main() {
int i = 47;
C1 o1;
o1.setvalue(i);
printf("value is %d\n", o1.getvalue());
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
Now, most of the time in production code, you'll see the member functions actually in a separate file. The class definition, or the interface, will be in a .h file, or sometimes .hpp, and the implementation, the member functions, will be in a .cpp file separate, but usually with the same name as the class.
Now when I build and run this next example, you'll notice that I'm calling both of these. For our mutable object, our object that does not have const, we're calling the one that says mutable and its value is 48, because its incrementing. For the one that's const safe, we're calling the const version and its value is zero because it does not get incremented. So we have here two functions with the same name, the only difference is that one is const safe and one is not. And so the const safe version only gets called for const objects.
#include <cstdio>
using namespace std;
class C1 {
int i = 0;
public:
void setvalue(int value);
int getvalue() const;
int getvalue();
};
void C1::setvalue(int value) {
i = value;
}
int C1::getvalue() const {
puts("const getvalue()");
return i;
}
int C1::getvalue() {
puts("mutable getvalue()");
return i;
}
int main() {
int i = 47;
C1 o1;
o1.setvalue(i);
printf("value is %d\n", o1.getvalue());
const C1 o2;
printf("value is %d\n", o2.getvalue());
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
mutable getvalue()
value is 47
const getvalue()
value is 0
2
3
4
So the rule of thumb is that a const safe function may always be called, and a non-const function may only be called by non-const objects. So if I have a function that doesn't actually need to change anything in the object, I'm always going to use the const keyword to make it const-safe. And if I have a function that actually needs to change something, then I don't use that. And if I need to have two versions for objects that are const and objects that are not, I can use the same name and overload that function and have a version for mutable objects and have a version for const safe objects.
So member functions are what make object-oriented programming possible. As we go through the rest of this chapter, you'll see that most of the other features of C++ objects are implemented with member functions.
# Constructors and destructors
Constructors and destructors are special member functions that serve a particular purpose. There are several types of constructors in C++.
So the first one's default constructor, second one is a constructor with operands, and the third one is called a copy constructor, and then there's a destructor.
#include <cstdio>
#include <string>
using namespace std;
const string unk = "unknown";
const string clone_prefix = "clone-";
// -- interface --
class Animal {
string _type = unk;
string _name = unk;
string _sound = unk;
public:
Animal(); // default constructor
Animal(const string & type, const string & name, const string & sound); // constructor with arguments
Animal(const Animal &); // copy constructor
~Animal(); // destructor
void print() const;
};
// -- implementation --
Animal::Animal() {
puts("default constructor");
}
Animal::Animal(const string & type, const string & name, const string & sound)
: _type(type), _name(name), _sound(sound) {
puts("constructor with arguments");
}
Animal::Animal(const Animal & a) {
puts("copy constructor");
_name = clone_prefix + a._name;
_type = a._type;
_sound = a._sound;
}
Animal::~Animal() {
printf("destructor: %s the %s\n", _name.c_str(), _type.c_str());
}
void Animal::print () const {
printf("%s the %s says %s\n", _name.c_str(), _type.c_str(), _sound.c_str());
}
int main() {
Animal a;
a.print();
const Animal b("goat", "bob", "baah");
b.print();
const Animal c = b;
c.print();
puts("end of main");
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
The constructor with arguments takes three string arguments, each of them is a constant reference to a string, and they're named type, name, and sound. These use the special class initializers. A constructor may initialize members before, or even without, executing a body of a constructor function. These initializations are very common and they're especially convenient and they look like this. So for each of these its the name of a private data member and so in this case we have type, name, and sound, each with an underscore before them. You see them here on lines 12 through 14. Then in parentheses is the value that is being used to initialize that private data member. So in this case its type, name, and sound these strings that are beings passed as parameters or as arguments to the constructor. So there's a colon that introduces this initialization section and it happens between that colon and the opening curly brace of the block. In this case the block, all it has in it is the puts for constructor with arguments. So again, this is something new, you haven't seen this before. its not common for functions, but it is very common for constructors in a class definition.
Animal::Animal(const string & type, const string & name, const string & sound)
: _type(type), _name(name), _sound(sound) {
puts("constructor with arguments");
}
2
3
4
The copy constructor, you see, it takes one argument and that argument is actually on the other side of an equals sign. So if we see this down here, we're defining const and the animal type and the name for the object, which is c, and an equals sign in b. So b is being used to initialize c by copying over its data. So here we put copy constructor and then we have these three lines of code which basically copy over the data from the right hand side of the equals sign, from the argument that's passed to this constructor. And you'll notice that we pre-panned the clone prefix to the name so that the name will say clone dash and then the name and we'll see that when we run this.
Animal::Animal(const Animal & a) {
puts("copy constructor");
_name = clone_prefix + a._name;
_type = a._type;
_sound = a._sound;
}
2
3
4
5
6
So I'm going to go ahead and I'm going to build and run this.
You can see what it does here. Our first one is the default constructor, and that's this one here. You'll notice that when we print it says unknown the unknown says unknown. That's because the default constructor doesn't do anything and that unknown string is the initialization for each of those data members.
Then we call the constructor with arguments. You see it says constructor with arguments and bob the goat says baah.
Then we call the copy constructor and you see it says copy constructor, it says clone-bob the goat says baah.
Then we put the string end of main and then you notice the destructors for each of these objects is called and that's because each of these is an automatic data, its data stored on the stack and when this block ends all of those objects are released. As they're released the destructors are called so that you can clean up memory, you can release resources and do whatever you need to do when your object is destroyed.
default constructor
unknown the unknown says unknown
constructor with arguments
bob the goat says baah
copy constructor
clone-bob the goat says baah
end of main
destructor: clone-bob the goat
destructor: bob the goat
destructor: unknown the unknown
2
3
4
5
6
7
8
9
10
So constructors and destructors are important parts of any C++ class. its always worth thinking carefully about how your objects are constructed and crafting constructors and destructors that handle all the necessary use cases.
# Constructors Another look
A constructor is a special type of method which runs everytime we instanciate an object.
// main.cpp
#include <iostream>
#include "Entity.h"
int main()
{
Entity e;
e.Print();
std::cin.get();
}
2
3
4
5
6
7
8
9
10
11
// Entity.cpp
#include "Entity.h"
#include <iostream>
void Entity::Print()
{
std::cout << X << ", " << Y << std::endl;
}
2
3
4
5
6
7
8
9
// Entity.h
#ifndef CONSTRUCTORSDESTRUCTORS_ENTITY_H
#define CONSTRUCTORSDESTRUCTORS_ENTITY_H
class Entity {
public:
float X, Y;
void Print();
};
#endif //CONSTRUCTORSDESTRUCTORS_ENTITY_H
2
3
4
5
6
7
8
9
10
11
12
13
When we run this It will work. However, we get seemingly random values for the position on this entity.
That's because when we instantiate this entity and allocated memory for It we didn't actually allocated memory for it, we didn't actually initialize that memory, meaning we got whatever was left over in that memory space. What we probably want to do is actually initialize the memory and set it to 0 o something like it, so our position is 0 by default if we don't specify or set a position.
1.4013e-45, 1.4013e-45
Another example is if we decide to manually print X and Y, they are public. Sometimes we can get an error C4700: uninitialized local variable 'e' used. Although, that wasn't the case on the code below, but is good to keep in mind that sometimes we can get an error for trying to use memory that have not been initialized.
// main.cpp
#include <iostream>
#include "Entity.h"
int main()
{
Entity e;
std::cout << e.X << std::endl;
e.Print();
std::cin.get();
}
2
3
4
5
6
7
8
9
10
11
12
So we need some kind of initialization so when we construct an entity we can be able to set X and Y to 0, unless we specify some value.
One way is to create an Init method for the class:
// main.cpp
#include <iostream>
#include "Entity.h"
int main()
{
Entity e;
e.Init();
std::cout << e.X << std::endl;
e.Print();
std::cin.get();
}
2
3
4
5
6
7
8
9
10
11
12
13
// Entity.cpp
#include "Entity.h"
#include <iostream>
void Entity::Init() {
X = 0.0f;
Y = 0.0f;
}
void Entity::Print()
{
std::cout << X << ", " << Y << std::endl;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
// Entity.h
#ifndef CONSTRUCTORSDESTRUCTORS_ENTITY_H
#define CONSTRUCTORSDESTRUCTORS_ENTITY_H
class Entity {
public:
float X, Y;
void Init();
void Print();
};
#endif //CONSTRUCTORSDESTRUCTORS_ENTITY_H
2
3
4
5
6
7
8
9
10
11
12
13
14
0
0, 0
2
Although everything is working, that's a lot of work and we have to initialize our entity everytime an entity is created.
To run the initialization when we construct the entity we have the constructor.
The constructor is a special method that gets called everytime you construct an entity.
To define it we define as any other method although It does not have a return type and It's name must match the name of the class.
// main.cpp
#include <iostream>
#include "Entity.h"
int main()
{
Entity e;
std::cout << e.X << std::endl;
e.Print();
std::cin.get();
}
2
3
4
5
6
7
8
9
10
11
12
// Entity.cpp
#include "Entity.h"
#include <iostream>
Entity::Entity() {
X = 0.0f;
Y = 0.0f;
}
void Entity::Print()
{
std::cout << X << ", " << Y << std::endl;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
// Entity.h
#ifndef CONSTRUCTORSDESTRUCTORS_ENTITY_H
#define CONSTRUCTORSDESTRUCTORS_ENTITY_H
class Entity {
public:
float X, Y;
Entity();
void Print();
};
#endif //CONSTRUCTORSDESTRUCTORS_ENTITY_H
2
3
4
5
6
7
8
9
10
11
12
13
14
15
0
0, 0
2
If you don't specify a constructor you still have a constructor It's called default constructor and It's provided for you by default. But It does nothing, It would be like this:
Entity::Entity() {
}
2
Java normally initialize the int and other variables and set to 0, but C++ just get what was left over on that memory.
# Constructors with parameters
Basically, I'm assigning my parameter to my member variable in this case.
// main.cpp
#include <iostream>
#include "Entity.h"
int main()
{
Entity e(10.0f, 6.0f);
std::cout << e.X << std::endl;
e.Print();
std::cin.get();
}
2
3
4
5
6
7
8
9
10
11
12
// Entity.cpp
#include "Entity.h"
#include <iostream>
Entity::Entity(float x, float y) {
X = x;
Y = y;
}
void Entity::Print()
{
std::cout << X << ", " << Y << std::endl;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
// Entity.h
#ifndef CONSTRUCTORSDESTRUCTORS_ENTITY_H
#define CONSTRUCTORSDESTRUCTORS_ENTITY_H
class Entity {
public:
float X, Y;
Entity(float x, float y);
void Print();
};
#endif //CONSTRUCTORSDESTRUCTORS_ENTITY_H
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# Overloading operators
Overloading operators is not unique to C++. In fact, it was one of the original concepts borrowed from ALGOL for C++ when it was first developed. But how C++ does it is fairly unique, and extremely powerful. There are two distinct ways to overload operators in C++. One is with member functions as part of the class definition and the other is as separate non-member functions.
Overloading means giving a new meaning to, or adding parameters to or creating essentially. In the case of Operator overloading you are allowed to define or change the behavior of an operator in your program.
#include <cstdio>
#include <iostream>
using namespace std;
class Rational {
int _n = 0;
int _d = 1;
public:
Rational ( int numerator = 0, int denominator = 1 ) : _n(numerator), _d(denominator) {};
Rational ( const Rational & rhs ) : _n(rhs._n), _d(rhs._d) {}; // copy constructor
~Rational ();
inline int numerator() const { return _n; };
inline int denominator() const { return _d; };
Rational & operator = ( const Rational & );
Rational operator + ( const Rational & ) const;
Rational operator - ( const Rational & ) const;
Rational operator * ( const Rational & ) const;
Rational operator / ( const Rational & ) const;
};
Rational::~Rational() {
_n = 0; _d = 1;
}
Rational & Rational::operator = ( const Rational & rhs ) {
if( this != &rhs ) {
_n = rhs.numerator();
_d = rhs.denominator();
}
return *this;
}
Rational Rational::operator + ( const Rational & rhs ) const {
return Rational((_n * rhs._d) + (_d * rhs._n), _d * rhs._d);
}
Rational Rational::operator - ( const Rational & rhs ) const {
return Rational((_n * rhs._d) - (_d * rhs._n), _d * rhs._d);
}
Rational Rational::operator * ( const Rational & rhs ) const {
return Rational(_n * rhs._n, _d * rhs._d);
}
Rational Rational::operator / ( const Rational & rhs ) const {
return Rational(_n * rhs._d, _d * rhs._n);
}
// useful for std::cout
std::ostream & operator << (std::ostream & o, const Rational & r) {
if(r.denominator() == 1) return o << r.numerator();
else return o << r.numerator() << '/' << r.denominator();
}
int main() {
Rational a = 7; // 7/1
cout << "a is: " << a << endl;
Rational b(5, 3); // 5/3
cout << "b is: " << b << endl;
Rational c = b; // copy constructor
cout << "c is: " << c << endl;
Rational d; // default constructor
cout << "d is: " << d << endl;
d = c; // assignment operator
cout << "d is: " << d << endl;
cout << a << " + " << b << " = " << a + b << endl;
cout << a << " - " << b << " = " << a - b << endl;
cout << a << " * " << b << " = " << a * b << endl;
cout << a << " / " << b << " = " << a / b << endl;
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
a is: 7
b is: 5/3
c is: 5/3
d is: 0
d is: 5/3
7 + 5/3 = 26/3
7 - 5/3 = 16/3
7 * 5/3 = 35/3
7 / 5/3 = 21/5
2
3
4
5
6
7
8
9
WARNING
Look to this lesson again
# Overloading operators with functions
We've already discussed operator overloads with member functions. In this lesson we'll look at why and how you may sometimes use non-member functions for your operator overloads.
#include <cstdio>
#include <iostream>
using namespace std;
class Rational {
int _n = 0;
int _d = 1;
public:
Rational(int numerator = 0, int denominator = 1) : _n(numerator), _d(denominator) {};
Rational(const Rational& rhs) : _n(rhs._n), _d(rhs._d) {}; // copy constructor
~Rational();
inline int numerator() const { return _n; };
inline int denominator() const { return _d; };
Rational & operator = (const Rational&);
// Rational operator + ( const Rational & ) const;
Rational operator - (const Rational&) const;
Rational operator * (const Rational&) const;
Rational operator / (const Rational&) const;
};
Rational::~Rational() {
_n = 0; _d = 1;
}
Rational & Rational::operator = (const Rational& rhs) {
if (this != &rhs) {
_n = rhs.numerator();
_d = rhs.denominator();
}
return *this;
}
Rational Rational::operator - (const Rational & rhs) const {
return Rational((_n * rhs._d) - (_d * rhs._n), _d * rhs._d);
}
Rational Rational::operator * (const Rational & rhs) const {
return Rational(_n * rhs._n, _d * rhs._d);
}
Rational Rational::operator / (const Rational & rhs) const {
return Rational(_n * rhs._d, _d * rhs._n);
}
Rational operator + (const Rational & lhs, const Rational & rhs) {
return Rational((lhs.numerator() * rhs.denominator()) + (lhs.denominator() * rhs.numerator()),
lhs.denominator() * rhs.denominator());
}
// useful for std::cout
std::ostream& operator << (std::ostream& o, const Rational& r) {
if (r.denominator() == 1) return o << r.numerator();
else return o << r.numerator() << '/' << r.denominator();
}
int main() {
Rational a = 7; // 7/1
cout << "a is: " << a << endl;
Rational b(5, 3); // 5/3
cout << "b is: " << b << endl;
Rational c = b; // copy constructor
cout << "c is: " << c << endl;
Rational d; // default constructor
cout << "d is: " << d << endl;
d = c; // assignment operator
cout << "d is: " << d << endl;
cout << a << " + " << b << " = " << a + b << endl;
cout << a << " - " << b << " = " << a - b << endl;
cout << a << " * " << b << " = " << a * b << endl;
cout << a << " / " << b << " = " << a / b << endl;
cout << 14 << " + " << b << " = " << 14 + b << endl;
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
a is: 7
b is: 5/3
c is: 5/3
d is: 0
d is: 5/3
7 + 5/3 = 26/3
7 - 5/3 = 16/3
7 * 5/3 = 35/3
7 / 5/3 = 21/5
14 + 5/3 = 47/3
2
3
4
5
6
7
8
9
10
So now the operator overload has two parameters, the left hand side and the right hand side. And this allows the compiler to convert our integer constant to a rational. Remember our implicit constructor. And now our operations work. There are definite circumstances where you'll want to use non-member functions for your operator overloads. And C++ supports this as well.
In a nutshell, whenever you have a constructor that allows implicit conversions. And if you come up here and you see we have these implicit conversions from a numerator and a denominator from integers. So whenever you have a constructor that allows implicit conversions, you'll want to think about non-member overload functions. These functions still go in your implementation file.
# 7. Templates
C++ Templates are marvelously simple and powerful. This is the C++ feature that supports generic programming. Generic programming refers to code that works independent of type while C++ is a strongly typed language, there's still great benefit in being able to write functions and classes that are type agnostic. That is, they operate on objects without concern for the type of those objects. Because C++ supports defining your own types through Classes and operator overloading. It is possible to do a great deal of generic programming in Templates while leaving implementation details to the Classes and Operators.
template <typename T>
T maxof (T a, T b) {
return ( a > b ? a : b)
}
2
3
4
Template Declarations look just like normal function or Class Declarations with one distinction; they are preceded by the Template keyword and a set of type identifiers.
These type identifiers are used as place holders by the template code to be replaced during compilation with actual types.
template <typename T>
class A {
T a;
public:
T getA() const { return a; }
void setA( T & x) { a = x; }
};
2
3
4
5
6
7
When a Function or Class is being used from a Template, the compiler generates a specialization of that Function or Class. Specifically suited to the types specified in the instantiation. This specialization is created at compiled time and one specialization is created for each Template for each set of data types.
template <typename T>
T maxof (T a, T b) {
return ( a > b ? a : b)
}
int x = 5;
int y = 10;
int z = maxof(x, y);
2
3
4
5
6
7
8
In this case "int z = maxof(x, y);" will compiled as:
int maxof ( int a, int b ) {
return ( a > b ? a : b );
}
2
3
Template programming is not entirely without its downsides. There are some issues you'll need to be aware of. Because the compiler must generate specializations for every type context of a Template, the amount of code to support that Template can grow rapidly with use. Compilers tend to have a difficult time generating sensible error messages with Templates. So, debugging can be challenging. Because Templates tend to live in Header files, changes to Header file with Templates can lead to recompilation of larger portions of your code than would otherwise be necessary.
C++ Templates are a very powerful feature that's also simple to implement and support. They have great advantages over other generic programming solutions. In particular, Preprocessor Macros and they're widely used to implement containers and other generic objects in the C++ Standard Library.
# Template functions
C++ supports both template functions and template classes. In this movie, we'll be looking at template functions.
here I have a simple template function that gives the maximum value of two parameters. To make it a template, we start with the template keyword, followed by a pair of angle brackets with the template argument list. The template argument list consists of one or more template argument where the word, typename, introduces a type alias, in this case, the capital letter T. Now, its worth mentioning here that the word typename is interchangeable with the word class in this particular context, and you may see class like this here in other people's code, especially in legacy code, written before the typename keyword was added to the language. Either of these tokens means the same thing. You'll often see people use the word class here. I strongly recommend that you use typename in this context because its less ambiguous.
So, the template declaration, with the template keyword, and the typename alias in angle brackets, this is what makes this function a template function.
#include <cstdio>
using namespace std;
template <typename T>
T maxof ( T a, T b ) {
return ( a > b ? a : b );
}
int main( int argc, char ** argv ) {
int m = maxof<int>( 7, 9 );
printf("max is: %d\n", m);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
max is: 9
Now that we've defined the alias with typename, the capital T can be used as a type anywhere you would use a type in the function. So, this is the maxof function, it returns a type T and it takes two type T arguments. This is type agnostic because it'll work for any class or type that supports the comparison operator that we're using here, and its type safe because the compiler generates a specialization of the function for each given type that uses this function. One important note, you cannot define a template within a block.
template <typename T>
T maxof ( T a, T b ) {
return ( a > b ? a : b );
}
2
3
4
So, now that we've defined the template, we can come down here and we can say int m equals maxof, and then, we have in angle brackets, the type int. So, this type is going to be used in place of the capital T in the specialization, and we say the maxof seven or nine, and it'll return a value, it'll return a nine in this case, and so, when I build and run, it says max is nine.
int main( int argc, char ** argv ) {
int m = maxof<int>( 7, 9 );
printf("max is: %d\n", m);
return 0;
}
2
3
4
5
max is: 9
Now, we can do this with all kinds of types here. We can say const char pointer, and say seven, and nine, and then this'll be a string, and of course we need a const char pointer for our type here, and now, when I build and run, it uses the same code and its the next one now. You'll notice that it says nine here, and if I reverse these, and you may get a different result on your system. Your system may not say nine as the result, and when I reverse these, you'll notice now it says seven. its not actually comparing the strings, what its comparing is the pointers, and that's because when we use the comparison operator on our const char pointer type, it compares the pointers, it doesn't compare the actual strings.
#include <cstdio>
using namespace std;
template <typename T>
T maxof ( T a, T b ) {
return ( a > b ? a : b );
}
int main( int argc, char ** argv ) {
const char * m = maxof<const char *>( "seven", "nine" );
printf("max is: %s\n", m);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
max is: seven
Well, we want to compare the actual strings. We can come up here and we can say, include and string, and now we can make this a string, and we can make this a string. Now this, we'll have to say, dot. Oops, string m, there we go, and this'll have to say, c string, and when I build and run, now it says seven because its actually comparing alphabetically. And if we reverse these, it should still say seven because the string type actually supports the comparison operator, and so, that's the determining factor here.
#include <cstdio>
#include <string>
using namespace std;
template <typename T>
T maxof ( T a, T b ) {
return ( a > b ? a : b );
}
int main( int argc, char ** argv ) {
string m = maxof<string>( "seven", "nine" );
printf("max is: %s\n", m.c_str());
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
max is: seven
Template functions are a form of generic programming that are easy to create and can be very useful for many of the purposes we used to use C Macros. C++ template functions are more powerful, more flexible, and less prone to error.
# Template classes
Template classes are commonly used for operating on containers.
So here we have a simple exception class and we'll talk more about exceptions later in this course. This is for error reporting. This is the LIFO stack class itself, notice we start with the template syntax, its the same as with template functions. We've the template keyword and then in angle brackets typename which could be the word class but I use typename, either one works and I consider this to be less ambiguous and a capital T which is a common abbreviation for the templated type so that T can be used anywhere, a type can be used. For example here we have a T pointer for stack pointer and this makes it independent of type, there is no code here at all that cares about what the type is. Here we've a constructor, which sets the size of the stack and notice this new T and size. We're allocating space based on a type that we don't even care about at this point, that'll happen when the specialization is created when the class is used. We've simple push and pop and the rest of it is so simple, that its just in-line, checking to see if the stack is empty checking to see if its full or returning the top element or the size of the stack. So, all of this is completely ambiguous to the type, that's being used with the class.
#include <iostream>
#include <string>
#include <exception>
using namespace std;
// simple exception class
class E : public std::exception {
const char * msg;
E(){}; // no default constructor
public:
explicit E(const char * s) throw() : msg(s) { }
const char * what() const throw() { return msg; }
};
// simple fixed-size LIFO stack template
template <typename T>
class bwstack {
private:
static const int defaultsize = 10;
static const int maxsize = 1000;
int _size;
int _top;
T * _stkptr;
public:
explicit bwstack(int s = defaultsize);
~bwstack() { delete[] _stkptr; }
T & push( const T & );
T & pop();
bool isempty() const { return _top < 0; }
bool isfull() const { return _top >= _size - 1; }
int top() const { return _top; }
int size() const { return _size; }
};
// Stack<T> constructor
template <typename T>
bwstack<T>::bwstack ( int s ) {
if(s > maxsize || s < 1) throw E("invalid stack size");
else _size = s;
_stkptr = new T[_size];
_top = -1;
}
template <typename T>
T & bwstack<T>::push ( const T & i ) {
if(isfull()) throw E("stack full");
return _stkptr[++_top] = i;
}
template <typename T>
T & bwstack<T>::pop () {
if(isempty()) throw E("stack empty");
return _stkptr[_top--];
}
int main( int argc, char ** argv ) {
try {
bwstack<int> si(5);
cout << "si size: " << si.size() << endl;
cout << "si top: " << si.top() << endl;
for ( int i : { 1, 2, 3, 4, 5 } ) {
si.push(i);
}
cout << "si top after pushes: " << si.top() << endl;
cout << "si is " << ( si.isfull() ? "" : "not " ) << "full" << endl;
while(!si.isempty()) {
cout << "popped " << si.pop() << endl;
}
} catch (E & e) {
cout << "Stack error: " << e.what() << endl;
}
try {
bwstack<string> ss(5);
cout << "ss size: " << ss.size() << endl;
cout << "ss top: " << ss.top() << endl;
for ( const char * s : { "one", "two", "three", "four", "five" } ) {
ss.push(s);
}
cout << "ss top after pushes: " << ss.top() << endl;
cout << "ss is " << ( ss.isfull() ? "" : "not " ) << "full" << endl;
while(!ss.isempty()) {
cout << "popped " << ss.pop() << endl;
}
} catch (E & e) {
cout << "Stack error: " << e.what() << endl;
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
si size: 5
si top: -1
si top after pushes: 4
si is full
popped 5
popped 4
popped 3
popped 2
popped 1
ss size: 5
ss top: -1
ss top after pushes: 4
ss is full
popped five
popped four
popped three
popped two
popped one
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
So, all of this is completely ambiguous to the type, that's being used with the class. So, here we're using bwstack with the int type and here we're using with the string type and if I go ahead and build and run, you notice that, I've initialized with stack size 5, the top is -1, the top is 4 after pushes, and the stack is full, so we pushed 5 items on and the top is zero based and here's the 5 values as we pop them off, popped 5, 4, 3, 2 and 1 and here it is the same with the string type and you know, we've got strings here and so we look at how this is used, its really similar we got it all tried back because we're using exceptions for error reporting and we're pushing these five items on the stack here in the integer version and we're pushing these five items of the stack in the string version. And so, its all very straight forward. It works beautifully, again its a very simple implementation of a stack.
# 8. Standard Library
The C++ Standard Library is used to support a large number of common system level tasks. This set of library functions is mostly inherited from the C Standard Library, and is generally compatible with the standard C code.
The standard library includes a great number of functions and macros supporting a broad scope of functionalities including facilities for creating and reading and writing files.
- fopen (filename, mode)
- fread (str, count, stream)
- fwrite (str, stream)
- fgets (buffer, size, count, stream)
- fputs (buffer, size, count, stream)
Support for C strings, null terminated arrays of characters.
- strncpy (dest, src, count)
- strncat (dest, src, count)
- strncmp (lhs, rhs)
- strnlen (str, count)
- strchr (str, ch)
- strstr (dest, src)
Error handling functions for standardized handling of UNIX style system errors.
- errno
- perror (s)
- strerror (errnum)
Date and time functions provide support for UNIX style date and time structures.
- time (time)
- gmtime (time)
- localtime (time)
- strftime (str, count, format, time)
And other utilities including math, localization, signals, and other system services.
- Math
- Localization
- Process control
- System services
The headers for the C++ Standard Library are the same as those for the C Standard Library with a simple difference.
For C++, the headers have no .h at the end of a file name, and have a lower case c at the beginning like these here. This effectively distinguishes the C++ library headers from the C versions, which are likely also included with your development system.
| C | C++ |
|:-------------------:|:------------------:|
| #include <stdio.h> | #include <cstdio> |
| #include <stdlib.h> | #include <cstdlib> |
| #include <string.h> | #include <cstring> |
| #include <errno.h> | #include <cerrno> |
2
3
4
5
6
These C++ library functions are in the standard name space. For compatibility with C code, many systems may not enforce this rule but you cannot count on this. So its always a good idea to use the standard namespace when using these functions.
using namespace std;
std::puts("Hello, World!");
2
3
These functions are all well documented. If you're on a Mac or any UNIX system you'll find documentation for these functions in the standard manpages. If you're using Windows or another non-UNIX development environment, you may look in the library documentation that comes with your developer environment, or by simply typing the name of the function into any major internet search engine.
# File I/O
Standard file IO is really very easy to do using the standard IO library. This is the C-compatible way to read and write a file. It's very low overhead, quick and simple.
You'll notice we have the C Standard IO header included and we've been using this in a lot of the example files where we were not doing file IO because it also has print out and puts, which are actually file IO, because in the Unix model, the console is simply another file stream.
// file-io.cpp by Bill Weinman <http://bw.org/>
// updated 2018-10-30
#include <cstdio>
using namespace std;
constexpr int maxstring = 1024; // read buffer size
constexpr int repeat = 5;
int main( int argc, char ** argv ) {
const char * fn = "testfile.txt"; // file name
const char * str = "This is a literal c-string.\n";
// create/write the file
printf("writing file\n");
FILE * fw = fopen(fn, "w");
for(int i = 0; i < repeat; i++) {
fputs(str, fw);
}
fclose(fw);
printf("done.\n");
// read the file
printf("reading file\n");
char buf[maxstring];
FILE * fr = fopen(fn, "r");
while(fgets(buf, maxstring, fr)) {
fputs(buf, stdout);
}
fclose(fr);
remove(fn);
printf("done.\n");
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
And so you'll notice when we get down here to actually writing to the file, we're using a version of puts called fputs, the difference being that it takes a file handle as its second argument. And we've opened the file handle here.
So this is where we open the file handle. We use fopen. And you'll notice the file handle is of this type, FILE *, all caps, with an asterisk, and that's the Unix type for a file handle, and it goes all the way back to the original versions of C back in the '70s, and it's a type def inside the standard IO header. So that's the type for a file. And we use fopen, and fopen takes two arguments. The first argument is the name of the file, which is defined up here on line 10, and then a file mode for opening, and in this case it's a w. The file mode is in quotes and it consists of one or more ASCII lowercase letters.
// create/write the file
printf("writing file\n");
FILE * fw = fopen(fn, "w");
for(int i = 0; i < repeat; i++) {
fputs(str, fw);
}
2
3
4
5
6
fopen() mode string
| Mode string | Meaning | If file exists | If file doesn't exist |
|---|---|---|---|
| r | Openfile for reading | Read from start | Failure |
| w | Create a file for writing | Destroy contents | Create new file |
| a | Append to a file | Write from end | Create new file |
| r++ | Open file for read/write | Read from start | Failure |
| w+ | Create file for read/write | Destroy contents | Create new file |
| a+ | Open file for read/write | Write from end | Create new file |
| b | Binary mode | - | - |
So fopen returns this file handle, which is fw, which is then in this loop our second argument to fputs, and what's it putting is the string that's defined up on line 11, and it's going to do that five times, while i is less than repeat. And you see up on line seven, repeat is defined as an integer number five.
And then we close the file, again using the file handle, and then we're going to open the file for reading.
fclose(fw);
printf("done.\n");
2
And so we define a buffer to read each line of the file into, and then we open the file using the fr file handle, and you'll notice that our mode string at this point is r for reading the file. So open the file to read from the beginning, and we use fgets to read into our buffer up to maxstring in length, and fputs to put that line from the buffer to standard out, which is the output stream, the file stream for the console. And so this is how we put these lines back on the console to display them. And then we close the file and remove or delete the file from the file system.
// read the file
printf("reading file\n");
char buf[maxstring];
FILE * fr = fopen(fn, "r");
while(fgets(buf, maxstring, fr)) {
fputs(buf, stdout);
}
2
3
4
5
6
7
And then we close the file and remove or delete the file from the file system. Remove of course takes the file name as its argument.
fclose(fr);
remove(fn);
2
So when I build and run this, it's very straightforward. It writes the file. And so it's writing five times this line of text, This is a literal c-string, new line. And so it writes that five times, and then it closes the file. Then it opens it for read and it reads them and displays them on the console, and then it says done and it closes the file and removes it.
writing file
done.
reading file
This is a literal c-string.
This is a literal c-string.
This is a literal c-string.
This is a literal c-string.
This is a literal c-string.
done.
2
3
4
5
6
7
8
9
So this is how to read and write a text file, and in the next lesson we'll cover binary files.
# Binary files
Reading and writing binary files is subtly different than text files, especially if you want to support an operating system that distinguishes between text files and binary files.
Let's take a look at this file:
// file-io-struct.cpp by Bill Weinman <http://bw.org/>
// updated 2018-10-30
#include <cstdio>
#include <cstring>
#include <cstdint>
using namespace std;
constexpr size_t maxlen = 111;
struct S {
uint8_t num;
uint8_t len;
char str[maxlen + 1];
};
int main( int argc, char ** argv ) {
const char * fn = "test.file"; // file name
const char * cstr = "This is a literal C-string.";
// create/write the file
printf("writing file\n");
FILE * fw = fopen(fn, "wb");
static struct S buf1;
for( int i = 0; i < 5; i++ ) {
buf1.num = i;
buf1.len = (uint8_t) strlen(cstr);
if(buf1.len > maxlen) buf1.len = maxlen;
strncpy(buf1.str, cstr, maxlen);
buf1.str[buf1.len] = 0; // make sure its terminated
fwrite(&buf1, sizeof(struct S), 1, fw);
}
fclose(fw);
printf("done.\n");
// read the file
printf("reading file\n");
FILE * fr = fopen(fn, "rb");
struct S buf2;
size_t rc;
while(( rc = fread(&buf2, sizeof(struct S), 1, fr) )) {
printf("a: %d, b: %d, s: %s\n", buf2.num, buf2.len, buf2.str);
}
fclose(fr);
remove(fn);
printf("done.\n");
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
You see I have a structure here and this structure includes two unsigned integer numbers integers. One of them is just a number for the purpose of being there and the other one is the length of this string. The maximum length of the string, the amount of space we're setting aside for this string is maxlen + 1 so it's 112 bytes and if you add in these 16 bits to that you get 128, which was the size that I wanted to get for this structure so that it fits on boundaries and memories. I tend to think like that so it's 128 byte structure.
struct S {
uint8_t num;
uint8_t len;
char str[maxlen + 1];
};
2
3
4
5
And then we come down here and we have the file name and a literal string that we're going to put in our string buffer in our structure.
int main( int argc, char ** argv ) {
const char * fn = "test.file"; // file name
const char * cstr = "This is a literal C-string.";
2
3
And then we're going to create a file for writing. Now we're using fopen again but this time you'll notice that our mode string is wb so it includes the "b" for binary file. Now some operating systems, notably Microsoft Windows, translate line endings and text files. So without the "b", such an operating system may assume that the file is text and may translate line endings for you which would alter the binary file. And in many instances it would make things just not work, unless you tell the operating system that this is a binary file and then it will not try to do that. So the "b" flag indicates binary mode and it tells the system not to translate line endings. The binary flag is generally ignored on systems where it's not needed, like Unix based operating systems like Mac OS, so it doesn't hurt anything if you use it whenever you work with non text files. So I strongly recommend that you always use it if you're working with a non text file.
int main( int argc, char ** argv ) {
const char * fn = "test.file"; // file name
const char * cstr = "This is a literal C-string.";
// create/write the file
printf("writing file\n");
FILE * fw = fopen(fn, "wb");
2
3
4
5
6
7
So we open the file with the binary mode, we declare a buffer of type struct S and it's in static memory space. And we have a loop that runs five times and we assign our number element to i so it'll be zero through four. We assign the length of the len element, the length element to be the length of the c string. And you notice I'm casting because strlen returns a size type, size t. And then we check to make sure that we have enough space, we copy over the string, we make sure that it's terminated with zero and then we write it. Now in this case we're writing the entire structure. We're not just writing a text string. So we're using fwrite instead of fputs and we give it the address of the buffer, the size of the buffer, the number of elements we're writing and the file handle.
static struct S buf1;
for( int i = 0; i < 5; i++ ) {
buf1.num = i;
buf1.len = (uint8_t) strlen(cstr);
if(buf1.len > maxlen) buf1.len = maxlen;
strncpy(buf1.str, cstr, maxlen);
buf1.str[buf1.len] = 0; // make sure its terminated
fwrite(&buf1, sizeof(struct S), 1, fw);
}
2
3
4
5
6
7
8
9
And we do this five times and then we close and then we read the file. And so now we open the file for read and again we have the "b" in our open mode and we set aside another structure and we read with fread which is very much like fwrite. And then we print out our structure just as we normally would with printf. And we close and we remove the file.
fclose(fw);
printf("done.\n");
// read the file
printf("reading file\n");
FILE * fr = fopen(fn, "rb");
struct S buf2;
size_t rc;
while(( rc = fread(&buf2, sizeof(struct S), 1, fr) )) {
printf("a: %d, b: %d, s: %s\n", buf2.num, buf2.len, buf2.str);
}
fclose(fr);
remove(fn);
2
3
4
5
6
7
8
9
10
11
12
13
14
So when I build and run you notice that it works exactly as expected with creating this binary file with binary data in it with these numbers and it has the string and we write it and then we read it back and we're done.
writing file
done.
reading file
a: 0, b: 27, s: This is a literal C-string.
a: 1, b: 27, s: This is a literal C-string.
a: 2, b: 27, s: This is a literal C-string.
a: 3, b: 27, s: This is a literal C-string.
a: 4, b: 27, s: This is a literal C-string.
done.
2
3
4
5
6
7
8
9
So if you want to support Microsoft Windows or other operating systems that treat text files differently you want to use the "b" flag whenever working with non text files and you can use fread and fwrite for reading and writing arbitrary signed buffers.
# File management
Let's take a quick look at how you can create, rename and delete files using the C++ standard library.
let's start by creating a files. We'll come down here and we'll give it a file name, and I'll say static const char pointer filename one equals file1 like that. And then I'm going to open a file now we know that when we open a file with the write mode it will create the file if the file didn't already exist. So this is actually the easiest way to create a file using file io. And so, I'm going to start with a file handle and use fopen and give it the filename and the write mode. And that create a file, if a file doesn't already exist. I can just right away close the file and I can say done.
#include <cstdio>
using namespace std;
int main() {
static const char * fn1 = "file1";
FILE * fh = fopen(fn1, "w");
fclose(fh);
puts("Done.");
return 0;
}
2
3
4
5
6
7
8
9
10
11
So now, when I build and run this it suspensively created a file, but where and how can I confirm this?
It goes to the debug directory
To rename, I'm going to simply say rename fn1 to fn2. And it's as simple as that. And when I build and run, it says done, and I can look at my working directory here and you see that is says file2 now instead of file1.
#include <cstdio>
using namespace std;
int main() {
static const char * fn1 = "file1";
static const char * fn2 = "file2";
rename(fn1, fn2);
puts("Done.");
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
And now if I want to delete it, I'll only need file2 for this, and I can say remove file2 and when I build and run and I go out and I look at it in my Finder you see that the file is gone and you should have the same results on a PC, or whatever platform that you're running on.
#include <cstdio>
using namespace std;
int main() {
static const char * fn1 = "file2";
remove(fn2);
puts("Done.");
return 0;
}
2
3
4
5
6
7
8
9
10
11
So, both rename and remove return zero on success, or non-zero value if there's an error. And we'll look at how to read the return error codes in a lesson on handling system errors. But for now, it's relatively simple to create, delete, and rename files using the C++ standard library and that's how you do it.
# Unformatted character I/O
The C++ standard library provides some simple functions for unformatted character I/O.
Here I have a working copy of working.cpp from chapter eight of the exercise files. And you'll notice down here on line seven this function puts which we've had in most of our working.cpp files. Puts simply displays text on the console. It works on the standard out file stream which is spelled S-T-D-O-U-T which is the default console. And it also sends a new line at the end of the string. So when I build and run you'll notice that it displays Hello World, it advances to the next line and then it ends and we get the message program ended with exit code zero.
#include <cstdio>
using namespace std;
int main() {
puts("Hello, world!");
return 0;
}
2
3
4
5
6
7
8
Hello, world!
Process finished with exit code 0
2
3
Now the other version of this is called fputs which takes as its second argument the output file handle. And in the Unix model that C++ is based upon standard out S-T-D-O-U-T is simply the file handle for the console and you can put any file handle you want there, you can use this to send output to a file, you can use it to send output to a socket to virtually anything that works with the standard Unix file system. The one difference between fputs and puts besides the file handle is that it does not send a new line at the end.
#include <cstdio>
using namespace std;
int main() {
fputs("Hello, world!", stdout);
return 0;
}
2
3
4
5
6
7
8
So if I build and run this you'll see that after Hello World it does not advanced to the next line and so the IDE's message that the program ended comes out on the same line as Hello World so we just put in a new line here and it works exactly as puts does.
Hello, world!
Process finished with exit code 0
2
Now if we want to read from the console type something in and have it read into our program we need to do a few things first. First, we'll declare a buffer size. So const int bufsize equals 256. And a buffer to hold the characters of size bufsize. And we'll put a prompt on the screen using fputs. And we will flush the output using fflush and I'll talk about this in a moment.
And then we're ready to read. And so we use fgets. And fgets takes a constant character pointer which we can give it our buffer. And a size which we can use as bufsize. So that's the size of the buffer so we'll read up to buffer minus one so that it can terminate it with a null. And the input stream which is standard in.
And then when we're all done I'll use fputs to display the buffer on the console. Send it to standard out. And I don't have to give it a new line because it reads the new line from when I hit the return key on the console.
#include <cstdio>
using namespace std;
int main() {
const int bufsize = 256;
static char buf[bufsize];
fputs("prompt: ", stdout);
fflush(stdout);
fgets(buf, bufsize, stdin);
fputs(buf, stdout);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
prompt:Thiago
Thiago
Process finished with exit code 0
2
3
4
So fgets is the function that gets characters from the console and it takes a buffer of buffer size and a file handle. So obviously it can also be used to read from files and you saw an example of this in our lessons on file I/O earlier in the chapter.
WARNING
It's worth noting that there's another version of gets just like there's a version of fputs that doesn't have the f and it's only for the console. There's a version of gets that likewise does not have the f and only works from the console and it's recommended that you never use it. In fact if you look at the man page for this. This is the man page from a Linux Programmer's Manual for GETS. And you notice in the description the very first words it says never use this function. And so we're not even going to read about it we're just going to scroll down here to BUGS section where it says never use gets because it is impossible to tell without knowing the data in advanced how many characters gets will read and because gets will continue to store characters past the end of the buffer it is extremely dangerous to use. It has been used to break computer security, use fgets instead. And it references use of inherently dangerous function. So never use gets by itself and nobody does anymore. It was part of the original C standard and for legacy systems it's still in the standard and it's still a library but it's ridiculously dangerous and ridiculously easy to abuse.
TIP
I also wanted to talk briefly about flushing the buffer. All the stream I/O in C++ is buffered. And so it's possible that you can send something out to the console or even out to a file and not have it actually get written to the console or not have it actually get written to the file and ends up sitting in the buffer for a long time. And so what fflush does is it simply flushes the buffer and it ensures that whatever characters you sent either to the console or to your file actually get written to the console or the file.
So these are the basic unformated character I/O functions in the C++ standard library.
# Formatted character I/O
The C++ Standard Library provides functions for formatted character output.
Printf is the most common function for formatting text in C and C++.
Printf takes a variadic number of arguments. So the first argument is the format string, so it's a const char string, const char pointer. And then, the arguments after that are variadic. There can be zero or many of those arguments, and that's dependent upon the format string itself.
#include <cstdio>
using namespace std;
int main() {
int i = 5;
long int li = 1234567890;
const char * s = "This is a string.";
printf("i is %d, li is %ld, s is %s\n", i, li, s);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
The format string has format specifiers like this one here. This is %d, so that's for an integer. This is %ld for a long integer, and here's %s for a c-string. So when I build and run, you see it replaces those format specifiers with the formatted output, and so it says "i is 5", "li is 1234567890", which is the long integer, and s is, this is a string.
i is 5, li is 1234567890, s is This is a string.
Printf writes to standard out. There's another version called fprintf, which takes as its first argument an output stream. So we can say stdout, and then after that becomes the format specifier, and the variadic arguments. And when we specify stdout, of course this works exactly as printf without the f. And of course you can put any output stream or file handle there to write to files or whatever you would like to do. And we've seen examples of that already in the lessons on character I/O.
#include <cstdio>
using namespace std;
int main() {
int i = 5;
long int li = 1234567890;
const char * s = "This is a string.";
fprintf(stdout,"i is %d, li is %ld, s is %s\n", i, li, s);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
And there's one other format that's worth noting, and that's %z or %zd, and for example, if we take the string length of this string here using strlen, that returns a size_t type, which is %zd and I can say, "length of s" and when I build and run, you see it says, "length of s is 17". And if I were to just use a regular %d for that, you notice I get an error, so click on this and you'll be able to read it. "Format specifies type 'int' but the argument has a type 'size_t' and it says "aka 'unsigned long'," because in this particular implementation, unsigned long is type deffed to size_t, but in different interpretations it would be different. So I could use an unsigned long here or I can just use zd for the size_t.
#include <cstdio>
#include <cstring>
using namespace std;
int main() {
int i = 5;
long int li = 1234567890;
const char * s = "This is a string.";
fprintf(stdout,"i is %d, li is %ld, s is %zd\n", i, li, strlen(s));
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
The printf function provides a great number of format specifiers for a vast array of different circumstances, this is a very small subset of the most common and useful specifiers. Any good C or C++ reference will have a more complete listing.
# String functions
The standard C++ library provides a number of functions for working with C-strings. These are different and distinct from the C++ STL string class. C-strings are simple, efficient, and flexible. They're often used where the complexity and power of an object-oriented string class is not necessary. These functions work on C-strings and are found in the cstring header.
At the top, we declare a bunch of variables that we're just going to use as we demonstrate these various functions. We have a size_t for the maximum size of a buffer, a couple of strings, a couple of buffers of maxbuf size, an integer, a character, and a character pointer.
// string.cpp by Bill Weinman <http://bw.org/>
#include <cstdio>
#include <cstring>
using namespace std;
int main() {
const static size_t maxbuf = 128;
const char * s1 = "String one";
const char * s2 = "String two";
char sd1[maxbuf];
char sd2[maxbuf];
int i = 0;
char c = 0;
char * cp = nullptr;
// strncpy -- copy a string
strncpy(sd1, s1, maxbuf);
printf("sd1 is %s\n", sd1);
strncpy(sd2, s2, maxbuf);
printf("sd2 is %s\n", sd2);
// strncat -- concatenate string
strncat(sd1, " - ", maxbuf - strlen(sd1) - 1);
strncat(sd1, s2, maxbuf - strlen(sd1) - 1);
printf("sd1 is %s\n", sd1);
// strnlen -- get length of string
printf("length of sd1 is %zd\n", strnlen(sd1, maxbuf));
printf("length of sd2 is %zd\n", strnlen(sd2, maxbuf));
// strcmp -- compare strings
i = strcmp(sd1, sd2);
printf("sd1 %s sd2 (%d)\n", (i == 0) ? "==" : "!=", i);
i = strcmp(sd2, s2);
printf("sd2 %s s2 (%d)\n", (i == 0) ? "==" : "!=", i);
// strchr -- find a char in string
c = 'n';
cp = strchr(sd1, c);
printf("Did we find a '%c' in sd1? %s\n", c, cp ? "yes" : "no");
if(cp) printf("The first '%c' in sd1 is at position %ld\n", c, cp - sd1);
// strstr -- find a string in string
cp = strstr(sd1, s2);
printf("Did we find '%s' in sd1? %s\n", s2, cp ? "yes" : "no");
if(cp) printf("The first '%s' in sd1 is at position %ld\n", s2, cp - sd1);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
Let's start with how to copy a string using strncpy. strncpy takes three arguments. The first argument is the destination, the second argument is the source, and the third argument is the size of the buffer available in the destination. And strncpy will copy, at most, up to maxbuf minus one characters, so there's room for a null terminator.
strncpy(sd1, s1, maxbuf);
printf("sd1 is %s\n", sd1);
strncpy(sd2, s2, maxbuf);
printf("sd2 is %s\n", sd2);
2
3
4
So, if I build and run here, you'll see the first couple lines. It says sd1 is String one and sd2 is String two, so I have successfully copied these strings using strncpy
sd1 is String one
sd2 is String two
2
strncat is for concatenating strings. And you notice that I call it twice here: once to add a space-dash-space, and the next time to add String two. And it takes three arguments. The first argument is the destination of the concatenation, the second argument is what is to be concatenated or the source, and then the third is the maximum number of characters to copy in the concatenation. And in this case, we're taking maxbuf and we're subtracting out the size of the destination string and minus one. And we do the same thing the second time we concatenate. And we concatenate String two.
// strncat -- concatenate string
strncat(sd1, " - ", maxbuf - strlen(sd1) - 1);
strncat(sd1, s2, maxbuf - strlen(sd1) - 1);
printf("sd1 is %s\n", sd1);
2
3
4
And you notice in our result down here, it says String one, space, dash, space, String two.
sd1 is String one - String two
strnlen is for getting the length of a string. And, again, this is a version that uses a maximum size. And it's always recommended that you use strnlen instead of strlen, which, some people use it, I may have even used on occasion, in this course. strnlen is safe because it has a maximum.
And so, if your string, for some reason, is not terminated, it won't just go and run all over memory.
// strnlen -- get length of string
printf("length of sd1 is %zd\n", strnlen(sd1, maxbuf));
printf("length of sd2 is %zd\n", strnlen(sd2, maxbuf));
2
3
And so, we see the length of sd1 is 23, and the length of sd2 is 10.
length of sd1 is 23
length of sd2 is 10
2
And then we compare strings using strcmp, str-C-M-P. strcmp returns a negative value if the left-hand side is less than the right-hand side, and returns a positive value if the left-hand side is greater than the right-hand side, and returns 0 if the two strings are equal. The absolute value of the result is not significant.
// strcmp -- compare strings
i = strcmp(sd1, sd2);
printf("sd1 %s sd2 (%d)\n", (i == 0) ? "==" : "!=", i);
i = strcmp(sd2, s2);
printf("sd2 %s s2 (%d)\n", (i == 0) ? "==" : "!=", i);
2
3
4
5
So, you see here, sd1 is not equal to sd2, and the result is -1 so it comes out as a less-than. And sd2 is equal to s2, and it returned a 0.
sd1 != sd2 (-1)
sd2 == s2 (0)
2
Str-C-H-R, strchr, is for finding a character in a string. And here we call it with the string as a first argument and as a character to look for in the second argument. Sometimes, you'll see them referred to as haystack and needle. And we use a ternary conditional operator to say yes or no as to whether or not it was found. It returns the position of the first matching character if it's found, or null if not. And so, that pointer, if it's null, then no, it wasn't found, and if it's not null, then yes, it was. And it returns the position.
And so, if I subtract, I can get the position in the string as an absolute number.
// strchr -- find a char in string
c = 'n';
cp = strchr(sd1, c);
printf("Did we find a '%c' in sd1? %s\n", c, cp ? "yes" : "no");
if(cp) printf("The first '%c' in sd1 is at position %ld\n", c, cp - sd1);
2
3
4
5
And so, down here, we say, yes, it was found and it's at position 4. And n is at position 4. Zero, one, two, three, four. And that is correct.
Did we find a 'n' in sd1? yes
The first 'n' in sd1 is at position 4
2
And we have strstr for searching for a string in a string and its return values are the same. It'll return null if it's not found, and a position if it is. And you can see we found String two in sd1, and we found it at position 13.
// strstr -- find a string in string
cp = strstr(sd1, s2);
printf("Did we find '%s' in sd1? %s\n", s2, cp ? "yes" : "no");
if(cp) printf("The first '%s' in sd1 is at position %ld\n", s2, cp - sd1);
2
3
4
Did we find 'String two' in sd1? yes
The first 'String two' in sd1 is at position 13
2
Even if you're using C++, you should never be afraid to use C-strings. There are times when they're necessary and there's times when they're just smaller and faster and more convenient than C++ SDL strings. And these functions are a great resource for working with C-strings.
# Handling system errors
The C++ standard library provides a few simple resources for handling system level error conditions.
conditions. Here I have a working copy of errno.cpp from chapter eight of the exercise files. This cerrno header provides access to the integer value errno, which we see here on line eight. If errno is zero, there's no error, and if it's not zero, will contain the value representing an error. The supported values and their meanings are typically defined by the host operating system, but it's easy for us to access them. For example, here I'm going to erase a file that doesn't exist.
#include <cstdio>
#include <cstring>
#include <cerrno>
int main() {
printf("errno is: %d\n", errno);
printf("Erasing file foo.bar\n");
remove("foo.bar");
printf("errno is: %d\n", errno);
perror("Cannot erase file");
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
And when I build and run, you'll notice that I get an errno of two. The errno is zero before the operation, and then errno is two after the operation. And I can use the perror function to report the error message associated with that errno, which in this case is no such file or directory. It's a common error.
Cannot erase file: No such file or directory
errno is: 0
Erasing file foo.bar
errno is: 2
Process finished with exit code 0
2
3
4
5
6
perror takes one argument which is a string, and this string is set to the standard error string, in this case, the console, and then a colon and a space and then the message associated with the current errno value.
perror("Cannot erase file");
Alternatively, I can use strerror and I can say const char pointer errstr equals strerror and give it the error number, and then I can print the error directly using printf.
#include <cstdio>
#include <cstring>
#include <cerrno>
int main() {
printf("errno is: %d\n", errno);
printf("Erasing file foo.bar\n");
remove("foo.bar");
printf("errno is: %d\n", errno);
const char * errstr = strerror(errno);
printf("the error string is: %s\n", errstr);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
And now when I build and run, it'll say the error string is, and of course I can say Tried to erase a file and this happened.
errno is: 0
Erasing file foo.bar
errno is: 2
Tried to erase a file and this happened: No such file or directory
Process finished with exit code 0
2
3
4
5
6
Now you need to include the cstring header in order to use the strerror function, and then you can do whatever you like with that error string. You can put it on the string, you can put it on the screen, or you can embed it in a file or whatever needs to be done.
So error numbers are very common in the standard library and these functions make it convenient to report errors based upon the error numbers.
# 9. Standard Template Labrary
The Standard Template Library is part of the C++ standard, so it's guaranteed to be part of every C++ development system. Commonly called the STL, the Standard Template Library provides containers and supporting data types like vectors, lists, queues, and iterators. Other basic functions are provided by the C++ standard library, the STL provides a number of standard containers.
Understanding the C++ Standard Template Library is an essential part of understanding C++. The STL is part of the C++ standard and it provides a great deal of basic functionality.
# Vectors
A vector is a sequence container that supports random access to its elements. You can think of it as an object-oriented array with a bunch of cool extra features. Vectors are extremely flexible.
The vector template class is defined in the vector header, which is right there, and we're using the int type in this example. Here we are initializing our vector. So this is a vector of integers.
You can initialize your vector with an initializer list, just like you can with an array. And vectors provide methods for accessing the current container size, the front and back elements and inserting and deleting elements.
// vector.cpp by Bill Weinman <http://bw.org/>
// updated 2018-10-31
#include <iostream>
#include <string>
#include <vector>
using namespace std;
int main() {
cout << "Vector from initializer list: " << endl;
vector<int> vi1 = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
cout << "size: " << vi1.size() << endl;
cout << "front: " << vi1.front() << endl;
cout << "back: " << vi1.back() << endl;
// iterator
cout << endl << "Iterator:" << endl;
vector<int>::iterator itbegin = vi1.begin();
vector<int>::iterator itend = vi1.end();
for (auto it = itbegin; it < itend; ++it) {
cout << *it << ' ';
}
cout << endl;
cout << endl << "Index:" << endl;
cout << "element at 5: " << vi1[5] << endl;
cout << "element at 5: " << vi1.at(5) << endl;
cout << endl << "Range-based for loop:" << endl;
for (int & i : vi1) {
cout << i << ' ';
}
cout << endl;
cout << endl << "Insert 42 at begin + 5: " << endl;
vi1.insert(vi1.begin() + 5, 42);
cout << "size: " << vi1.size() << endl;
cout << "vi1[5]: " << vi1[5] << endl;
cout << "Erase at begin + 5: " << endl;
vi1.erase(vi1.begin() + 5);
cout << "size: " << vi1.size() << endl;
cout << "vi1[5]: " << vi1[5] << endl;
cout << "push_back 47: " << endl;
vi1.push_back(47);
cout << "size: " << vi1.size() << endl;
cout << "vi1.back() " << vi1.back() << endl;
cout << "Range-based for loop: " << endl;
for(int & v : vi1) {
cout << v << ' ';
}
cout << endl << endl;
// from C-array
const static size_t size = 10;
int ia[size] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
cout << endl << "Vector from C-array: " << endl;
vector<int> vi2(ia, ia + size);
for( int & i : vi2 ) {
cout << i << ' ';
}
cout << endl << endl;
// vector of strings
cout << "Vector of strings:" << endl;
vector<string> vs = { "one", "two", "three", "four", "five" };
for(string & v : vs) {
cout << v << endl;
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
So if we go ahead and build and run this. We're going to walk through this a little bit at a time, and we'll look at the results here as we do that.
Vector from initializer list:
size: 10
front: 1
back: 10
Iterator:
1 2 3 4 5 6 7 8 9 10
Index:
element at 5: 6
element at 5: 6
Range-based for loop:
1 2 3 4 5 6 7 8 9 10
Insert 42 at begin + 5:
size: 11
vi1[5]: 42
Erase at begin + 5:
size: 10
vi1[5]: 6
push_back 47:
size: 11
vi1.back() 47
Range-based for loop:
1 2 3 4 5 6 7 8 9 10 47
Vector from C-array:
1 2 3 4 5 6 7 8 9 10
Vector of strings:
one
two
three
four
five
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
Here we have the size, and the front element, and the back element of the vector. So the size is 10, the front element is one, and the back element is 10.
cout << "size: " << vi1.size() << endl;
cout << "front: " << vi1.front() << endl;
cout << "back: " << vi1.back() << endl;
2
3
Vector from initializer list:
size: 10
front: 1
back: 10
2
3
4
Here we're using an iterator to use a for loop through the vector. And you'll notice that I declare the iterator with the same vector type, and two colons and the iterator. And this may be a bit cumbersome.
// iterator
cout << endl << "Iterator:" << endl;
vector<int>::iterator itbegin = vi1.begin();
vector<int>::iterator itend = vi1.end();
for (auto it = itbegin; it < itend; ++it) {
cout << *it << ' ';
}
cout << endl;
2
3
4
5
6
7
8
Iterator:
1 2 3 4 5 6 7 8 9 10
2
You can always use auto because the begin and the end member functions return the iterator. So I can use auto here and auto there, just like I'm using auto here in the loop. And so if I build and run, you'll see here is our iterator and we're iterating through the loop just fine.
// iterator
cout << endl << "Iterator:" << endl;
auto itbegin = vi1.begin();
auto itend = vi1.end();
for (auto it = itbegin; it < itend; ++it) {
cout << *it << ' ';
}
cout << endl;
2
3
4
5
6
7
8
Iterator:
1 2 3 4 5 6 7 8 9 10
2
You can index the vector just as you would an array, using the index operator, or you can use the at function. And you'll notice here the element of five is six in both instances.
cout << endl << "Index:" << endl;
cout << "element at 5: " << vi1[5] << endl;
cout << "element at 5: " << vi1.at(5) << endl;
2
3
Index:
element at 5: 6
element at 5: 6
2
3
You can use the range based for loop which is self explanatory and very simple.
cout << endl << "Range-based for loop:" << endl;
for (int & i : vi1) {
cout << i << ' ';
}
cout << endl;
2
3
4
5
Range-based for loop:
1 2 3 4 5 6 7 8 9 10
2
And you can insert elements, erase elements, and push elements on the back.
And so here we have insert, begin plus five is where we're going to be inserting it so that first argument takes an iterator to point at the position.
cout << endl << "Insert 42 at begin + 5: " << endl;
vi1.insert(vi1.begin() + 5, 42);
cout << "size: " << vi1.size() << endl;
cout << "vi1[5]: " << vi1[5] << endl;
2
3
4
Insert 42 at begin + 5:
size: 11
vi1[5]: 42
2
3
You can erase using the same syntax, so that erases the element.
cout << "Erase at begin + 5: " << endl;
vi1.erase(vi1.begin() + 5);
cout << "size: " << vi1.size() << endl;
cout << "vi1[5]: " << vi1[5] << endl;
2
3
4
Erase at begin + 5:
size: 10
vi1[5]: 6
2
3
And you can push an element onto the back.
cout << "push_back 47: " << endl;
vi1.push_back(47);
cout << "size: " << vi1.size() << endl;
cout << "vi1.back() " << vi1.back() << endl;
2
3
4
push_back 47:
size: 11
vi1.back() 47
2
3
And the range-based for loop just to show us our whole vector. We can see that it's expanded one in size, and it's still working just fine.
cout << "Range-based for loop: " << endl;
for(int & v : vi1) {
cout << v << ' ';
}
cout << endl << endl;
2
3
4
5
Range-based for loop:
1 2 3 4 5 6 7 8 9 10 47
2
You can initialize a vector from a C-array and so here I have an array, and I give it the index of the beginning and the index just past the end. And that'll initialize the vector from the array.
// from C-array
const static size_t size = 10;
int ia[size] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
cout << endl << "Vector from C-array: " << endl;
vector<int> vi2(ia, ia + size);
for( int & i : vi2 ) {
cout << i << ' ';
}
cout << endl << endl;
2
3
4
5
6
7
8
9
Vector from C-array:
1 2 3 4 5 6 7 8 9 10
2
Of course, you can use any type with your vectors. Here we are using STL strings with our vector. And you'll notice that that works exactly as expected.
// vector of strings
cout << "Vector of strings:" << endl;
vector<string> vs = { "one", "two", "three", "four", "five" };
for(string & v : vs) {
cout << v << endl;
}
2
3
4
5
6
Vector of strings:
one
two
three
four
five
2
3
4
5
6
The vector is a fundamental container type, that's very powerful and easy to use. Use it wherever you would otherwise use a C-array but could benefit from some of the capabilities the vector provides. While the vector is the most common, the STL provides a number of container types.
# Strings
The STL string class is a special type of container specifically designed to operate with sequences of characters. It's designed with many features to operate on strings efficiently and intuitively.
String is an STL container class that operates on characters in the same way as any sequence container class operates on other types. String has functions that are specifically designed for operating on a string of characters, it works a lot like a vector, but with string-related functions. And it's defined in the string header.
So, here we declare a string s1, and an iterator, and you notice we use that same colon, colon, iterator syntax for declaring our iterator.
// string.cpp by Bill Weinman <http://bw.org/>
// updated 2018-10-31
#include <iostream>
#include <string>
using namespace std;
int main() {
string s1 = "This is a string";
string::iterator it;
// size & length
cout << "size is same as length: " << s1.size() << endl;
cout << "size is same as length: " << s1.length() << endl;
// + for concatenation
cout << "concatenated strings: ";
string s2 = "this is also a string";
cout << s1 + ":" + s2 << endl;
// compare
cout << "is s1 == s2? " << (s1 == s2 ? "yes" : "no") << endl;
cout << "copy-assign s2 = s1" << endl;
s2 = s1;
cout << "is s1 == s2? " << (s1 == s2 ? "yes" : "no") << endl;
cout << "is s1 > \"other string\"? " << (s1 > "other string" ? "yes" : "no") << endl;
cout << "is s1 < \"other string\"? " << (s1 < "other string" ? "yes" : "no") << endl;
cout << "is \"other string\"? > s1 " << ("other string" > s1 ? "yes" : "no") << endl;
cout << "is \"other string\" < s1? " << ("other string" < s1 ? "yes" : "no") << endl;
// iteration
cout << "each character: ";
for( char c : s1 ) {
cout << c << " ";
}
cout << endl;
// insert & erase with an iterator
it = s1.begin() + 5;
s1.insert(it, 'X');
cout << "after insert: " << s1 << endl;
it = s1.begin() + 5;
s1.erase(it);
cout << "after erase: " << s1 << endl;
// replace
s1.replace(5, 2, "ain't");
cout << "after replace: " << s1 << endl;
// substr
cout << "substr: " << s1.substr(5, 5) << endl;
// find
size_t pos = s1.find("s");
cout << "find first \"s\" in s1 (pos): " << pos << endl;
// rfind
pos = s1.rfind("s");
cout << "find last \"s\" in s1 (pos): " << pos << endl;
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
size is same as length: 16
size is same as length: 16
concatenated strings: This is a string:this is also a string
is s1 == s2? no
copy-assign s2 = s1
is s1 == s2? yes
is s1 > "other string"? no
is s1 < "other string"? yes
is "other string"? > s1 yes
is "other string" < s1? no
each character: T h i s i s a s t r i n g
after insert: This Xis a string
after erase: This is a string
after replace: This ain't a string
substr: ain't
find first "s" in s1 (pos): 3
find last "s" in s1 (pos): 13
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
You notice that size and length are the same. Size is used in the rest of the STL for the other container classes, and length is simply an alias that seems more string-like.
// size & length
cout << "size is same as length: " << s1.size() << endl;
cout << "size is same as length: " << s1.length() << endl;
2
3
size is same as length: 16
size is same as length: 16
2
You may concatenate strings using the plus operator, so here we declare another string s2. And we concatenate it with a colon, and our result here is this is a string, and this is also a string, with a colon in between.
// + for concatenation
cout << "concatenated strings: ";
string s2 = "this is also a string";
cout << s1 + ":" + s2 << endl;
2
3
4
concatenated strings: This is a string:this is also a string
You can use the normal comparison operators double equals, greater than, less than, and the like. And these all operate on the string according to its colation, which by default is standard utf aid, or ascii. And here, we're checking if s1 is the same as s2, no it's not, and then we assign s1 to s2, and we see that now they are the same. We check for greater than, and less than using a literal string, other string, and we can see that we get the results that we expect there.
// compare
cout << "is s1 == s2? " << (s1 == s2 ? "yes" : "no") << endl;
cout << "copy-assign s2 = s1" << endl;
s2 = s1;
cout << "is s1 == s2? " << (s1 == s2 ? "yes" : "no") << endl;
cout << "is s1 > \"other string\"? " << (s1 > "other string" ? "yes" : "no") << endl;
cout << "is s1 < \"other string\"? " << (s1 < "other string" ? "yes" : "no") << endl;
cout << "is \"other string\"? > s1 " << ("other string" > s1 ? "yes" : "no") << endl;
cout << "is \"other string\" < s1? " << ("other string" < s1 ? "yes" : "no") << endl;
2
3
4
5
6
7
8
9
is s1 == s2? no
copy-assign s2 = s1
is s1 == s2? yes
is s1 > "other string"? no
is s1 < "other string"? yes
is "other string"? > s1 yes
is "other string" < s1? no
2
3
4
5
6
7
We can iterate through the string classes if it were any other container. And we get the individual characters, which we can see right here.
// iteration
cout << "each character: ";
for( char c : s1 ) {
cout << c << " ";
}
cout << endl;
2
3
4
5
6
each character: T h i s i s a s t r i n g
We can use our iterator to insert and erase, so we set it to begin plus five, and we can insert an x, and here we are inserting the x at just after the fifth position, and we can erase it as well, and there it is gone. And we can replace with an index. You notice here at position five, we're replacing two characters, and those two characters are the is, and we're replacing it with the five characters ain't.
// insert & erase with an iterator
it = s1.begin() + 5;
s1.insert(it, 'X');
cout << "after insert: " << s1 << endl;
it = s1.begin() + 5;
s1.erase(it);
cout << "after erase: " << s1 << endl;
// replace
s1.replace(5, 2, "ain't");
cout << "after replace: " << s1 << endl;
2
3
4
5
6
7
8
9
10
11
12
after insert: This Xis a string
after erase: This is a string
after replace: This ain't a string
2
3
We can get the substring, starting at position five for five characters and we get that ain't, and we can search for the first s, and we find the position of that at position three, and the last s using r find, and we find that that's at position 13.
// substr
cout << "substr: " << s1.substr(5, 5) << endl;
// find
size_t pos = s1.find("s");
cout << "find first \"s\" in s1 (pos): " << pos << endl;
// rfind
pos = s1.rfind("s");
cout << "find last \"s\" in s1 (pos): " << pos << endl;
2
3
4
5
6
7
8
9
10
substr: ain't
find first "s" in s1 (pos): 3
find last "s" in s1 (pos): 13
2
3
The STL string class is a powerful and flexible string class, implemented as a sequence container. It has a rich set of features, and an intuitive interface. For more detail on STL strings, please see the companion course C++ Templates and the STL.
# I/O streams
The iostream library is fairly rich, but most of it's there as back end support and there's really just a few classes that you'll normally use.
// iostream-formatting.cpp by Bill Weinman <http://bw.org/>
// updated 2018-10-31
#include <iostream>
#include <string>
#include <iomanip>
using namespace std;
int main() {
// cout and cin to get a string
string istr;
cout << "Prompt: ";
cin >> istr; // one word at a time
cout << "Input: " << istr << endl;
// integer formatting
cout << "Integer formatting:" << endl;
int i1 = 42;
int i2 = 127;
int i3 = 5555;
cout << "default: " << i1 << ' ' << i2 << ' ' << i3 << endl;
cout << "hex: " << hex << i1 << ' ' << i2 << ' ' << i3 << endl;
cout << "hex with showbase: " << showbase << hex << i1 << ' ' << i2 << ' ' << i3 << endl;
cout << "octal with showbase: " << oct << i1 << ' ' << i2 << ' ' << i3 << endl;
cout << "default: " << noshowbase << dec << i1 << ' ' << i2 << ' ' << i3 << endl;
// floating point formatting options
cout << endl << "Floating point formatting:" << endl;
double d1, d2, d3;
d1 = 3.1415926534;
d2 = 1234.5;
d3 = 4.2e-10;
cout << "default: " << d1 << ' ' << d2 << ' ' << d3 << ' ' << endl;
cout << "fixed: " << fixed << d1 << ' ' << d2 << ' ' << d3 << ' ' << endl;
cout << "scientific: " << scientific << d1 << ' ' << d2 << ' ' << d3 << ' ' << endl;
cout << "fixed (3): " << setprecision(3) << fixed << d1 << ' ' << d2 << ' ' << d3 << ' ' << endl;
cout << "scientific (7): " << setprecision(7) << scientific << d1 << ' ' << d2 << ' ' << d3 << ' ' << endl;
cout.unsetf(ios_base::floatfield);
cout << "default: " << d1 << ' ' << d2 << ' ' << d3 << ' ' << endl;
// string formatting options
cout << endl << "String formatting:" << endl;
string s1 = "This is a string.";
string s2 = "This is a much longer string.";
string s3 = "Today's news: Big Light in Sky Slated to Appear in East";
cout << s1 << endl;
cout << s2 << endl;
cout << s3 << endl;
cout << setw(64) << right << s1 << endl;
cout << setw(64) << right << s2 << endl;
cout << setw(64) << right << s3 << endl;
cout << setfill('-') << setw(64) << right << s1 << endl;
cout << setfill(' ') << setw(64) << right << s1 << endl;
cout << left << s1 << endl;
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
write the file:
read the file:
1 This is the test file
2 This is the test file
3 This is the test file
delete file.
Process finished with exit code 0
2
3
4
5
6
7
8
9
iostreams come in two basic flavors. Input streams and output streams. We're going to take a quick look at an input stream here and then we'll look at some output stream formatting.
// iostream-formatting.cpp by Bill Weinman <http://bw.org/>
// updated 2018-10-31
#include <iostream>
#include <string>
#include <iomanip>
using namespace std;
int main() {
// cout and cin to get a string
string istr;
cout << "Prompt: ";
cin >> istr; // one word at a time
cout << "Input: " << istr << endl;
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
So when I build and run this, notice I get our prompt which is what we expect, and I can type in a few words here. Here is a few words, and when I press return you'll notice that it just displays the first of those words, here and that's because cin reads the input one word at a time.
Prompt:here are a few words
Input: here
Process finished with exit code 0
2
3
4
If instead, you want to read in line oriented input you can use a method of cin called get line and that works like this, first we'll declare a buffer. And then we can say cin.getline and give it our buffer and the size of the buffer, and then when I display here instead of istring I'll say buffer, buf.
#include <iostream>
#include <string>
#include <iomanip>
using namespace std;
int main() {
// cout and cin to get a string
string istr;
cout << "Prompt: ";
char buf[128];
cin.getline(buf, sizeof(buf));
cout << "Input: " << buf << endl;
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Now when I build and run this you notice that I will get all of the words. So here is a bunch of words and when I press enter we get here is a bunch of words. So this is line oriented as opposed to the word oriented from before.
Prompt:Here are a bunch of words
Input: Here are a bunch of words
Process finished with exit code 0
2
3
4
# Integer Formatting
Now we can focus on the output formatting iostream uses manipulators to set flags that modify the behavior of the stream. We've seen cout do things like this, integer formatting with endl to indicate the end of a line, and that's pretty common and if I build and run this, you can see what that looks like I'll scroll up to the top there. There's the integer formatting and the end of the line and then I initialize these three integers and I print them out default i1, i2, i3 and end of line and we've seen this before and so that's how that works. I can modify this to display the integers in hexadecimal by using the hex modifier. You see there they are in hexadecimal, I can add showbase and what showbase does is it puts the 0x before each of them. I can print them out in octal and because showbase is set they have a zero before each of them and here they are in octal, and I can go back to default by setting nowshowbase and decimal and so that gives us our default again. So this is some integer formatting.
cout << "Integer formatting:" << endl;
int i1 = 42;
int i2 = 127;
int i3 = 5555;
cout << "default: " << i1 << ' ' << i2 << ' ' << i3 << endl;
cout << "hex: " << hex << i1 << ' ' << i2 << ' ' << i3 << endl;
cout << "hex with showbase: " << showbase << hex << i1 << ' ' << i2 << ' ' << i3 << endl;
cout << "octal with showbase: " << oct << i1 << ' ' << i2 << ' ' << i3 << endl;
cout << "default: " << noshowbase << dec << i1 << ' ' << i2 << ' ' << i3 << endl;
2
3
4
5
6
7
8
9
Integer formatting:
default: 42 127 5555
hex: 2a 7f 15b3
hex with showbase: 0x2a 0x7f 0x15b3
octal with showbase: 052 0177 012663
default: 42 127 5555
2
3
4
5
6
# Floating point formatting
We can also format floating point numbers and here we have floating point formatting. We have three doubles and we notice that the third one is a very small number e minus 10 and so that's using scientific notation to initialize that double and so by default, they're printed like this. There's our little bit of pie, and one 1234.5, and the 4.2 e minus 10 you notice that our little bit of pie here 3.14159 we actually had a number of more digits than that, now we'll see later that we can set our precisions to get more digits if we want to. So we can give them fixed number of precision and so you see it defaults to these six digits to the right of the decimal point, we can say scientific notation and scientific notation it gives us these numbers in scientific notation, all three of them. We can say fixed with a precision of three so it gives us just three digits to the right of the decimal point and you notice that for our very small number this is not even nearly enough to display the e minus 10, and then scientific notation with a set precision of seven digits and so again that's seven digits to the right of the decimal point. So we have 3.1415927 and you notice its rounding because it's 265, and the other one's also in the scientific with fixed precision.
If we want to get back to default, we simply say unsetf for unset all the flags. Ios_base::floatfield and that will reset all of the floating point manipulators.
// floating point formatting options
cout << endl << "Floating point formatting:" << endl;
double d1, d2, d3;
d1 = 3.1415926534;
d2 = 1234.5;
d3 = 4.2e-10;
cout << "default: " << d1 << ' ' << d2 << ' ' << d3 << ' ' << endl;
cout << "fixed: " << fixed << d1 << ' ' << d2 << ' ' << d3 << ' ' << endl;
cout << "scientific: " << scientific << d1 << ' ' << d2 << ' ' << d3 << ' ' << endl;
cout << "fixed (3): " << setprecision(3) << fixed << d1 << ' ' << d2 << ' ' << d3 << ' ' << endl;
cout << "scientific (7): " << setprecision(7) << scientific << d1 << ' ' << d2 << ' ' << d3 << ' ' << endl;
cout.unsetf(ios_base::floatfield);
cout << "default: " << d1 << ' ' << d2 << ' ' << d3 << ' ' << endl;
2
3
4
5
6
7
8
9
10
11
12
13
Floating point formatting:
default: 3.14159 1234.5 4.2e-10
fixed: 3.141593 1234.500000 0.000000
scientific: 3.141593e+00 1.234500e+03 4.200000e-10
fixed (3): 3.142 1234.500 0.000
scientific (7): 3.1415927e+00 1.2345000e+03 4.2000000e-10
default: 3.141593 1234.5 4.2e-10
2
3
4
5
6
7
# String formatting
We can also format strings and I'll scroll down here so we can see our string formatting. Here's our three strings and we print them out just by default with endl and there they are. We can set a width and right format them so we set 64 characters and we right format them. So here they are right formatted, this is a string a much longer string and big light in the sky slated to appear in east. We can set the fill to be dashes instead of spaces and then set it back to spaces and then we can set it back to left formatting. Endl we've talked a little bit about this, it's a special purpose manipulator that provides an end of line character and it also flushes the output string.
// string formatting options
cout << endl << "String formatting:" << endl;
string s1 = "This is a string.";
string s2 = "This is a much longer string.";
string s3 = "Today's news: Big Light in Sky Slated to Appear in East";
cout << s1 << endl;
cout << s2 << endl;
cout << s3 << endl;
cout << setw(64) << right << s1 << endl;
cout << setw(64) << right << s2 << endl;
cout << setw(64) << right << s3 << endl;
cout << setfill('-') << setw(64) << right << s1 << endl;
cout << setfill(' ') << setw(64) << right << s1 << endl;
cout << left << s1 << endl;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
String formatting:
This is a string.
This is a much longer string.
Today's news: Big Light in Sky Slated to Appear in East
This is a string.
This is a much longer string.
Today's news: Big Light in Sky Slated to Appear in East
-----------------------------------------------This is a string.
This is a string.
This is a string.
Process finished with exit code 0
2
3
4
5
6
7
8
9
10
11
12
Iostream can also be used for writing to and reading from files, so here we set up an integer and the file name test.txt and a text string and we write a file, and so we use ofstream to open a file. Ofstream is a class and the object will be ofile and we're passing it the file name to initialize it, and then we can use it just like a stream, and so we put out the line number in the text string and endl and we can use ifstream to read the file back and just like ofstream we create an object.
We initialize it with the file name and then we use this loop here, checking to see that we're still good and using get line to read line by line from our infile and cout to send it to the console and so when I build and run. You see here is our file as we read the file one, two, three, our line numbers, and the text, and then we delete the file with the remove function which we find in the cstdio library we've seen that before.
// iostream-file.cpp by Bill Weinman <http://bw.org/>
// updated 2018-10-31
#include <cstdio>
#include <iostream>
#include <string>
#include <fstream>
using namespace std;
int main() {
static int lineno = 0;
static const char * filename = "test.txt";
static const char * textstring = "This is the test file";
// write a file
cout << "write the file:" << endl;
ofstream ofile(filename);
ofile << ++lineno << " " << textstring << endl;
ofile << ++lineno << " " << textstring << endl;
ofile << ++lineno << " " << textstring << endl;
ofile.close();
// read a file
static char buf[128];
cout << "read the file:" << endl;
ifstream infile(filename);
while (infile.good()) {
infile.getline(buf, sizeof(buf));
cout << buf << endl;
}
infile.close();
// delete file
cout << "delete file." << endl;
remove(filename);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
write the file:
read the file:
1 This is the test file
2 This is the test file
3 This is the test file
delete file.
Process finished with exit code 0
2
3
4
5
6
7
8
9
So the iostream library is very useful for basic generalized io including interfacing with the console and writing to and reading from files. For more control you may use the cstandard library functions for reading and writing files.
# Handling exceptions
The standard exception class is designed to declare objects to be thrown as exceptions. The exception class has a virtual function called what that returns a C-string. Thing function can be overloaded in derived classes to provide a description of the exception.
exception.cpp from chapter nine of the exercise files, and you'll notice down here we have a function called broken, and this function, all it does is it throws an exception using the default exception class, and down here we have main, which calls broken. It says, "let's have an emergency!".
// exception.cpp by Bill Weinman <http://bw.org/>
// updated 2018-10-31
#include <iostream>
#include <exception>
using namespace std;
class E : public exception {
const char * msg;
E();
public:
E(const char * s) throw() : msg(s) {}
const char * what() const throw() { return msg; }
};
void broken() {
cout << "this is a broken function" << endl;
throw exception();
}
int main() {
cout << "lets have an emergency!" << endl;
broken();
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
So, let's go ahead and build and run this and see what happens.
C:\Users\Thiago Souto\Desktop\VUEPRESS\PROGRAMMING\docs\Resources\C++\Ex_Files_CPlusPlus_EssT\working.cpp(17,5): error: cannot use 'throw' with exceptions disabled
throw exception();
^
1 error generated.
NMAKE : fatal error U1077: 'C:\PROGRA~2\MICROS~4\2019\COMMUN~1\VC\Tools\Llvm\bin\clang-cl.exe' : return code '0x1'
Stop.
NMAKE : fatal error U1077: '"C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.25.28610\bin\HostX86\x86\nmake.exe"' : return code '0x2'
Stop.
NMAKE : fatal error U1077: '"C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.25.28610\bin\HostX86\x86\nmake.exe"' : return code '0x2'
Stop.
NMAKE : fatal error U1077: '"C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.25.28610\bin\HostX86\x86\nmake.exe"' : return code '0x2'
Stop.
2
3
4
5
6
7
8
9
10
11
12
We got an error, so how can we make this operate a little bit better? Well, we can catch our exception, and I do this with a try block. (typing) try, (typing) and catch, and in this case I'm going to catch with the exception class, and I'll give it a reference and an object, (typing) and here in the exception block I'll simply say cout, and e.what, (typing) and endl.
// exception.cpp by Bill Weinman <http://bw.org/>
// updated 2018-10-31
#include <iostream>
#include <exception>
using namespace std;
class E : public exception {
const char * msg;
E();
public:
E(const char * s) throw() : msg(s) {}
const char * what() const throw() { return msg; }
};
void broken() {
cout << "this is a broken function" << endl;
throw exception();
}
int main() {
cout << "lets have an emergency!" << endl;
try {
broken();
} catch (exception & e) {
cout << e.what() << endl;
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
I can build mym own exception messages like so:
#include <iostream>
#include <exception>
using namespace std;
class E : public exception {
const char * msg;
E();
public:
E(const char * s) throw() : msg(s) {}
const char * what() const throw() { return msg; }
};
const E e_ouch("ouch!")
const E e_bad("bad code!")
const E e_worse("don't do that!")
void broken() {
cout << "this is a broken function" << endl;
throw e_worse;
}
int main() {
cout << "lets have an emergency!" << endl;
try {
broken();
} catch (E & e) {
cout << e.what() << endl;
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
C++ exceptions provide a simple and effective way of handling errors and other exceptional circumstances at runtime. The standard exception class is well-suited for deriving objects to be thrown as exceptions for a variety of usages.
WARNING
Find exceptions using cmake and Clion